多集群 & 多租户
# 一、多集群
注意:下面讨论的前提是单个机房内的多集群。
# 1.1 多集群的必要性
对于类似账号服务的 L0 级别的服务,几乎所有的服务都有依赖,需要尽可能的提高服务的可用性。
- 从单一集群考虑:多个节点保证可用性,我们通常使用 N+2 的方式来冗余节点(N 一般通过压测得出);
- 从单一集群故障带来的影响面角度考虑:冗余多套集群,例如依赖的 redis 出现问题,整个集群挂掉了;
- 从单个机房内的机房故障考虑:多机房部署,如果在云上可能是多个可用区。
# 1.2 如何实现多集群
- 多套冗余的集群 对应多套独占的缓存,带来更好的性能和冗余能力;
- 要尽量 避免按照业务划分 集群资源,业务隔离集群带来的问题是缓存命中率下降,不同业务形态数据正交,可以退而求其次整个集群全部连接。
# 1.3 如何降低健康检查流量
对于账号这种大量服务依赖的服务,仅仅是健康检查流量就可能会导致 30% 以上的资源占用(B 站之前的真实情况)。可以使用 子集算法 从全集群中选取一批节点(子集),利用划分子集限制连接池大小。
- 通常 20~100 个后端,部分场景需要大子集,比如大批量读写操作;
- 算法核心:后端节点平均分给客户端;
- 客户端重启,保持重新均衡,同时对后端重启保持透明,同时连接的变动最小。即:消费者节点数变化的时候需要重新平衡,且变动尽可能小。
子集算法的实现如下:
// from google sre
func Subset(backends []string, clientID, subsetSize int) []string {
subsetCount := len(backends) / subsetSize
// Group clients into rounds; each round uses the same shuffled list:
round := clientID / subsetCount
r := rand.New(rand.NewSource(int64(round)))
r.Shuffle(len(backends), func(i, j int) { backends[i], backends[j] = backends[j], backends[i] })
// The subset id corresponding to the current client:
subsetID := clientID % subsetCount
start := subsetID * subsetSize
return backends[start : start+subsetSize]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
为什么上面这个算法可以保证可以均匀分布?
首先,shuffle 算法保证在 round 一致的情况下,backend 的排列一定是一致的。
因为每个实例拥有从 0 开始的连续唯一的自增 id,且计算过程能够保证每个 round 内所有实例拿到的服务列表的排列一致,因此在同一个 round 内的 client 会分别选择 backend 排列的不同部分的切片作为选中的后端服务来建立连接。
下面通过示例运行一遍该算法:
backends:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
clientID:0~9
subsetSize:4
划分结果:
Round 0: [0, 6, 3, 5, 1, 7, 11, 9, 2, 4, 8, 10]
|---C0---| |---C1----| |---C2----|
Round 1: [8, 11, 4, 0, 5, 6, 10, 3, 2, 7, 9, 1]
|---C4---| |---C5----| |---C6----|
Round 2: [8, 3, 7, 2, 1, 4, 9, 10, 6, 5, 0, 11]
|---C7---| |---C8----| |---C9----|
2
3
4
5
6
7
8
所以只要 client id 是连续的,那么 client 发向后端的连接就一定是连续的。
# 二、多租户
在一个微服务架构中允许 多系统共存 是利用微服务稳定性以及模块化最有效的方式之一,这种方式一般被称为多租户。租户可以是测试、金丝雀发布、影子系统(shadow systems),甚至服务层或者产品线,使用租户能够 保证代码的隔离性 并且能够 基于流量租户做路由决策。
# 2.1 多测试环境
实际场景
假设现在有一个服务调用链 A -> B -> C,如果 C 同时有多个同学开发,如果甲同学的代码正在测试中,但是乙同学不小心发了一个版本,就会导致甲同学的代码被冲掉,导致测试同学测着测着就出现 bug。测试同学无法得知这个问题是由于环境导致的还是代码缺陷。
解决方案 1:多套物理环境
搭建多套测试环境,可以做到物理隔离,但是也会存在一些问题:
- 混用环境导致的不可靠测试;
- 多套环境带来的硬件成本;
- 难以做负载测试,仿真线上真实流量情况;
- 治标不治本,无法知道当前环境谁在使用,并且几套环境可以满足需求?万一又多几个人开发是不是又需要再来几套?
解决方案 2:多租户,染色发布
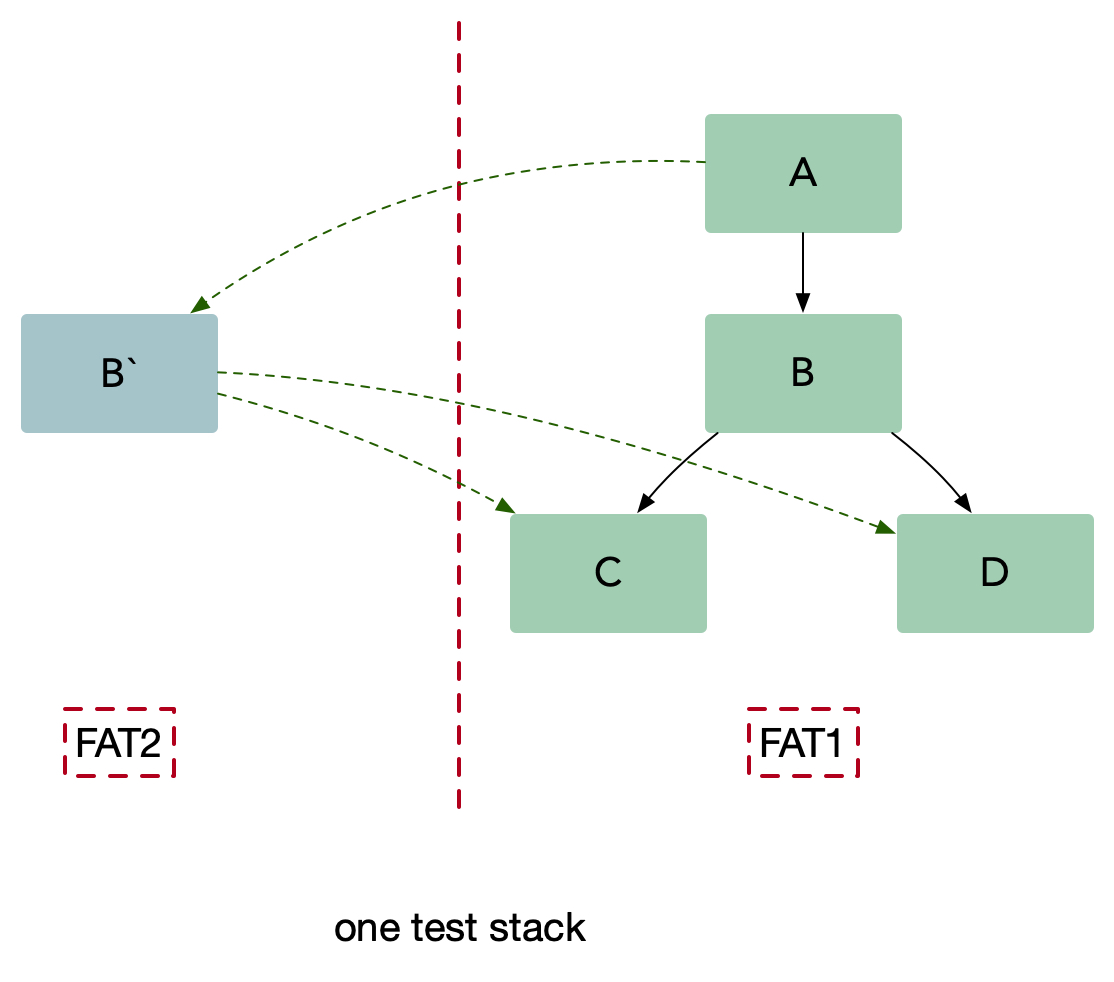
- 待测试的服务 B 在一个隔离的沙盒环境中启动,并且在沙盒环境下可以访问集成环境(UAT)C 和 D;
- 测试流量路由到服务 B,同时保持生产流量正常流入到集成服务,服务 B 仅仅处理测试流量而不处理生产流量;
- 另外要确保集成流量不要被测试流量影响。
生产中的测试提出了两个基本要求,它们也构成了多租户体系结构的基础:
- 流量路由:能够基于流入栈中的流量类型做路由;
- 隔离性:能够可靠的隔离测试和生产中的资源,这样可以保证对于关键业务微服务没有副作用。
具体实现方法如下:
- 注册时:测试服务需要带上染色标签;
- 测试时:需要在 Http 请求头中打上该标签,并在服务间透传;
- 负载均衡策略:将原始的数组结构修改为 Map 结构,优先染色标签路由。
# 2.2 全链路压测
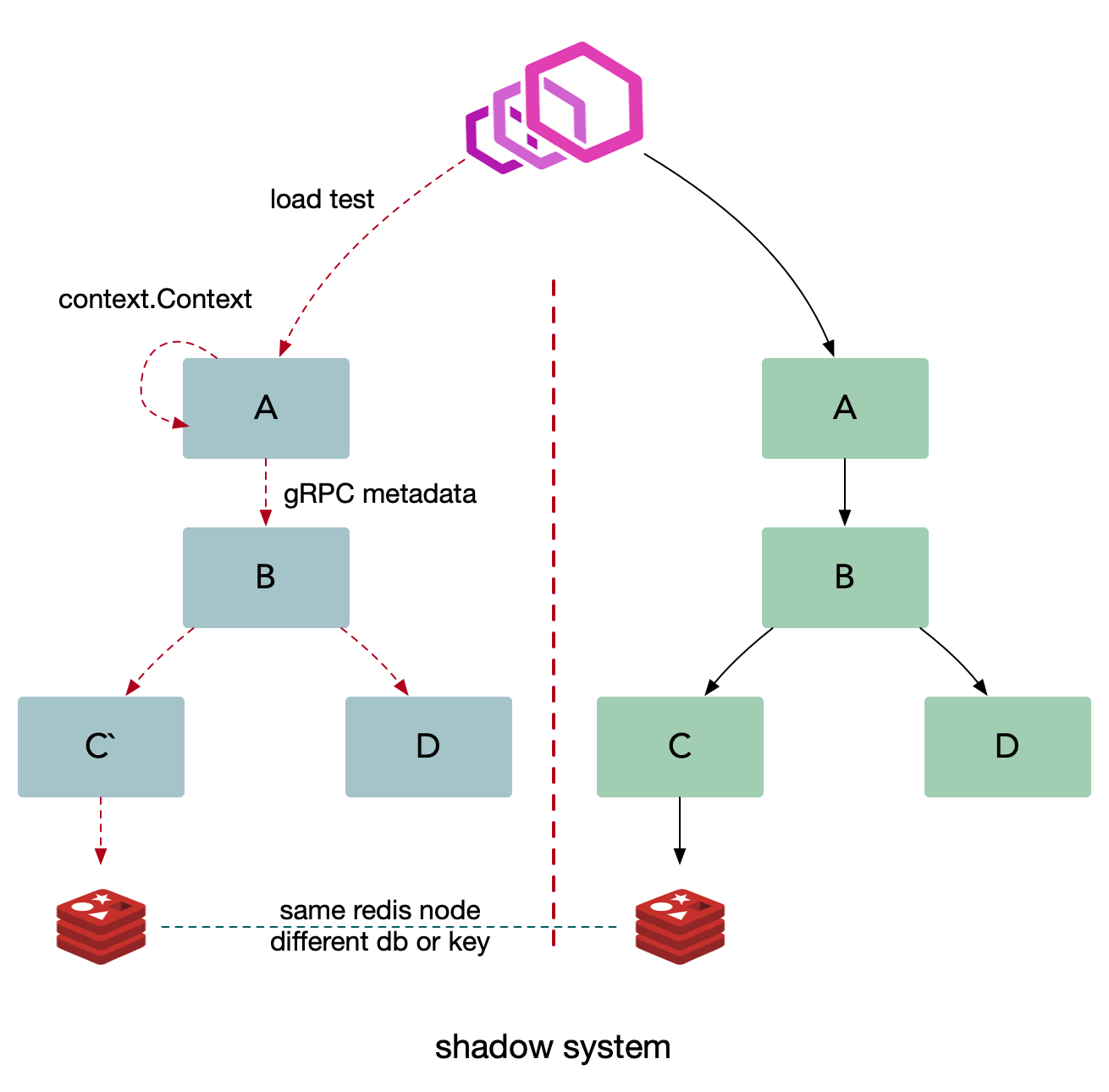
和上面的测试环境的解决方案类似,但是我们需要搭建一套和线上一致的影子系统。
- 基础设施需要做改造,采用同样的基础设施节点;
- 缓存:影子应用存储的数据放到影子库中,使用不同的 db;
- 数据库:自动将线上的数据结构复制一份到影子数据库中,里面的表结构保持一致,数据库名做一些变化,例如 db_shadow;
- 消息队列:推送消息的时候使用不同的 topic 或者是携带一些 metadata 信息;
- 需要提前做一些数据初始化的操作,提前进行准备;
- 压测时携带压测标签,将流量自动路由到影子服务进行压测。
这种方案同样可以用于灰度发版当中。