gRPC & 服务发现
# 一、gRPC 简介
gRPC 是什么可以用官网的一句话来概括 “A high-performance, open-source universal RPC framework”,即高性能、开源的通用 RPC 框架。
# 1.1 gRPC 的优势
- 多语言:语言中立,支持多种语言;
- 轻量级、高性能:序列化支持 PB(Protocol Buffer)和 JSON,PB 是一种语言无关的高性能序列化框架;
- 可插拔:支持插件;
- IDL:基于文件定义服务,通过 proto3 工具生成指定语言的数据结构、服务端接口以及客户端 Stub;
- 设计理念:RPC 支持元数据传递,可以自定义 metadata;
- 移动端:基于 标准的 HTTP2 设计,支持双向流、消息头压缩、单 TCP 的多路复用、服务端推送 等特性,这些特性使得 gRPC 在移动端设备上更加 省电和节省网络流量;
- 服务而非对象、消息而非引用:促进微服务的系统间粗粒度消息交互设计理念;
- 负载无关的:不同的服务需要使用不同的消息类型和编码,例如 protocol buffers、JSON、XML 和 Thrift;
- 流:Streaming API;
- 阻塞式和非阻塞式:支持异步和同步处理在客户端和服务端间交互的消息序列;
- 元数据交换:常见的横切关注点,如认证或跟踪,依赖数据交换;
- 标准化状态码:客户端通常以有限的方式响应 API 调用返回的错误。
# 1.2 Restful 的不足
- 需要单独写文档,常常会因为代码更新了但是文档没更新陷入坑中;
- 性能不太好,JSON 传递相对于 PB 更耗流量,性能更低;
- http1.1 是一个单连接的请求,在内部网络环境,使用 http 比较浪费;
- Restful 是一个 松散约束 的协议,非常灵活,每个人、每个团队出来的代码都不太一样,比较容易出错。
# 二、健康检查
gRPC 有一个标准的健康检测协议,在 gRPC 的所有语言实现中基本都提供了生成代码和用于设置运行状态的功能。基于该健康检查功能,可以平滑的实现应用的发布与下线,下面分别介绍其具体流程。
# 2.1 平滑发布
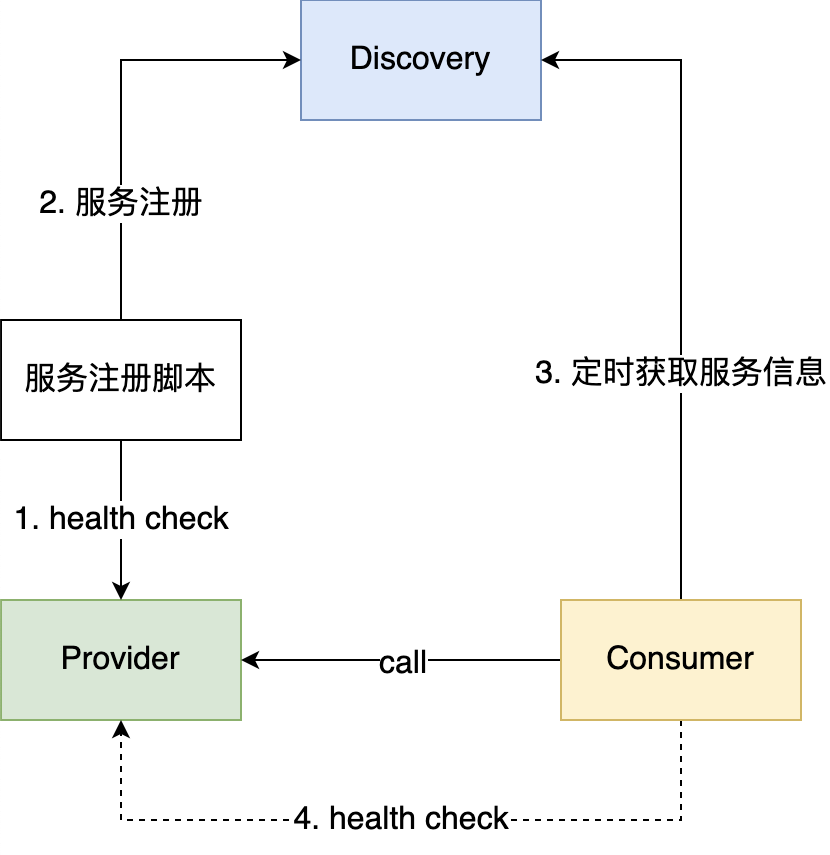
- Provider 启动,k8s 中的服务注册脚本会定时去调用 Provider 的健康检查接口;
- 健康检查通过之后,服务注册脚本向注册中心 Discovery 注册服务(消息形式:
rpc://ip:port); - 消费者 Consumer 定时从服务注册中心获取服务方地址信息;
- 获取成功后,会定时的向服务方发起健康检查,健康检查通过后才会向这个地址发起请求;
- 在运行过程中如果健康检查出现问题,会从消费者本地的负载均衡中移除。
以上这种服务注册方式也叫 外挂注册,即:不是在 Provider 代码中进行服务注册,而是有一个单独的服务注册脚本在健康检查后进行注册的。
# 2.2 平滑下线

- 触发下线操作:首先用户在发布平台点击发版 / 下线按钮;
- 发布部署平台向注册中心发起服务注销请求,在注册中心下线服务的这个节点;
- 注册中心下线应用之后,消费者会获取到服务注销的事件,然后将服务方的节点从本地负载均衡当中移除。
- 发布部署平台向应用发送
SIGTERM信号,应用捕获到之后执行:- 将健康检查接口设置为不健康;
- 调用 grpc/http 的 shutdown 接口,并且传递超时时间(一般为 2 个心跳周期),等待连接全部关闭后退出。
- 发布部署平台如果发现应用程序长时间没有完成退出,发送
SIGKILL强制退出应用;- 这个超时时间根据应用进行设置一般为 10 ~ 60s。
# 三、服务发现
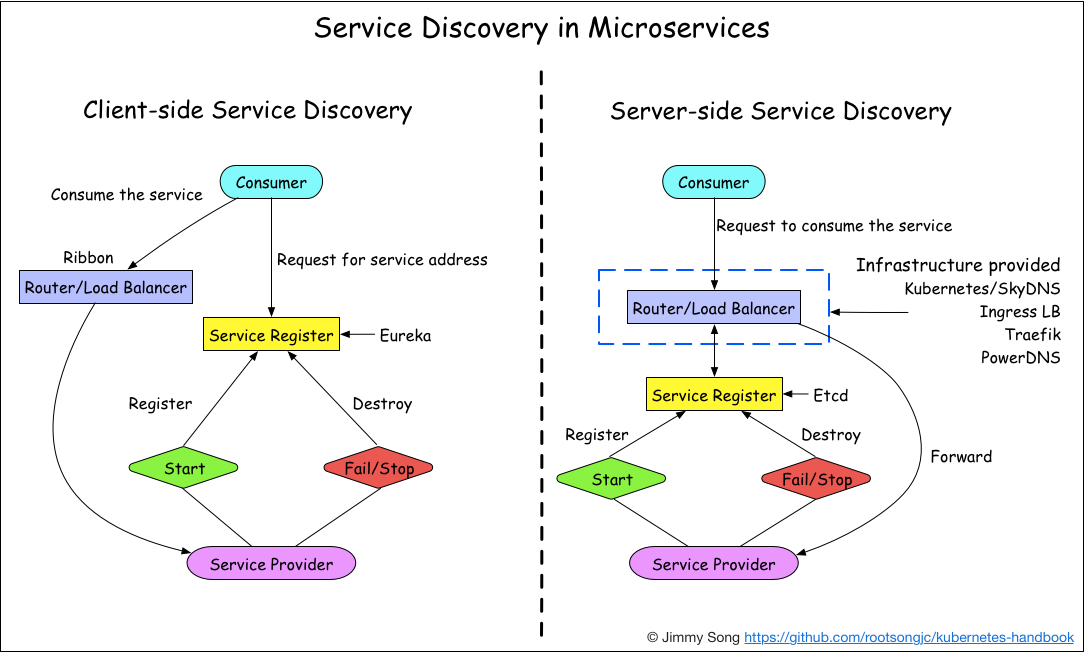
# 3.1 客户端发现
一个服务实例被启动时,它的网络地址会被写到注册表上,当服务实例终止时,再从注册表中删除,这个服务实例的注册表通过心跳机制动态刷新。客户端使用一个负载均衡算法,去选择一个可用的服务实例,来响应这个请求。
- 优势:直连,比服务端服务发现少一次网络跳转;
- 不足:Consumer 需要内置特定的服务发现客户端和发现逻辑。
- 可以将负载均衡逻辑下放到 Sidecar 中进行解耦。
# 3.2 服务端发现
客户端通过负载均衡器向一个服务发送请求,这个负载均衡器会查询服务注册表,并将请求路由到可用的服务实例上。服务实例在服务注册表上被注册和注销,常见的实现方式有 Consul Template + Nginx、kubernetes + etcd。
- 优势:Consumer 无需关注服务发现具体细节,只需知道服务的 DNS 域名即可,支持异构语言开发;
- 不足:需要基础设施支撑,多了一次网络跳转,可能有性能损失。
# 3.3 注册中心
CP、CA、还是 AP
实际场景是海量服务发现和注册,服务状态可以弱一致,需要的是 AP 系统,只需最终一致性即可。
- 注册的事件延迟:高可用的服务在这方面问题不大;
- 注销的事件延迟:因为有上文提到的健康检查的机制,即使注销延迟,客户端也会主动的将节点移除。
多个注册中心的对比如下表所示,推荐使用阿里开源的注册中心:Nacos (opens new window)。
| Nacos | Eureka | Consul | CoreDNS | Zookeeper | |
|---|---|---|---|---|---|
| 一致性协议 | CP + AP | AP | CP | — | CP |
| 健康检查 | TCP / HTTP / MYSQL / Client Beat | Client Beat | TCP / HTTP / gRPC / Cmd | — | Keep Alive |
| 负载均衡策略 | 权重 / metadata / Selector | Ribbon | Fabio | RoundRobin | — |
| 雪崩保护 | 有 | 有 | 无 | 无 | 无 |
| 自动注销实例 | 支持 | 支持 | 不支持 | 不支持 | 支持 |
| 访问协议 | HTTP / DNS | HTTP | HTTP / DNS | DNS | TCP |
| 监听支持 | 支持 | 支持 | 支持 | 不支持 | 支持 |
| 多数据中心 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 跨注册中心同步 | 支持 | 不支持 | 支持 | 不支持 | 不支持 |
| SpringCloud 集成 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| Dubbo 集成 | 支持 | 不支持 | 不支持 | 不支持 | 支持 |
| K8s 集成 | 支持 | 不支持 | 支持 | 支持 | 不支持 |
说明
CAP 定理(CAP theorem),又被称作 布鲁尔定理(Brewer's theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency):所有节点在同一时间的数据完全一致;
- 可用性(Availability):服务在正常响应时间内一直可用;
- 分区容错性(Partition tolerance):分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务。
理解 CAP 理论的最简单方式是想象两个节点分处分区两侧:
- 允许至少一个节点更新状态会导致数据不一致,即丧失了 C 性质;
- 如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了 A 性质;
- 除非两个节点可以互相通信,才能既保证 C 又保证 A,这又会导致丧失 P 性质。
Eureka 实现原理
B 站仿照用 Go 写了一个 bilibili/discovery (opens new window)

- 服务注册
- 注册:服务方启动后向注册中心任意一个节点发送注册请求,然后这个节点会向其他节点进行 广播同步;
- 心跳:注册后定期(30s)向注册中心发送心跳;
- 下线:下线时向注册中心发送下线请求。
注意:注册中心节点启动时需要加载缓存进行预热,所以不建议这个时候服务进行重启或者是发版。
- 服务发现
- 消费者定期向注册中心长轮询获取节点信息,获取到之后缓存到本地。
- 网络故障
- 服务方 与 注册中心:注册中心会定期(60s)检测已失效(90s 未更新)的实例,失效之后就会移除,但是如果短时间内丢失大量心跳连接(15min 内心跳低于期望值的 85%),就会开启自我保护模式,保留过期的服务不会进行删除;
- 消费者 与 注册中心:消费者本地有缓存,问题不大;
- 服务方 与 消费者:有健康检查,健康检查不通过时,会从消费者本地负载均衡中移除。
- 注册中心故障
- 不建议这个时候服务进行重启或者是发版,因为这个时候注册不上,会导致服务不可用,不发版短时间没有影响;
- 根据挂掉的节点数量,有不同的处理方式:
- 如果全部挂掉,启动后必须要等两到三个心跳周期,等所有的服务都注册上之后,再开始提供服务运行消费者拉取数据;
- 如果挂掉一个,需要等其他的节点将信息同步到本机之后再提供服务。
说明:数据同步时会对比时间戳,会保证当前节点的数据是最新的。