数据类型概述
# 一、String(字符串)
Redis 的 String 能表达 3 种值的类型:字符串、整数、浮点数。
# 1.1 常见操作命令
| 命令 | 使用方法 | 说明 |
| set | set key value | 赋值 |
| set key value NX | 键不存在时赋值 | |
| set key value PX 100 | 设置键的过期时间为 100 毫秒 | |
| get | get key | 取值 |
| getset | getset key value | 取值并赋值 |
| append | append key value | 向尾部追加值 |
| strlen | strlen key | 获取字符串长度 |
| incr | incr key | 递增数字 |
| incrby | incrby key increment | 增加指定的整数 |
| decr | decr key | 递减数字 |
| decrby | decrby key decrement | 减少指定的整数 |
# 1.2 应用场景
- 普通的赋值
- 乐观锁:incr 命令
- 分布式锁:set 命令的 NX 参数
# 二、List(列表)
List 列表类型可以存储有序、可重复的元素,获取头部或尾部附近的记录是极快的。
List 的元素个数最多为 ,约 40 亿个。
# 2.1 常见操作命令
| 命令 | 使用方法 | 说明 |
|---|---|---|
| lpush | lpush key v1 v2 v3 ... | 从左侧插入列表 |
| lpop | lpop key | 从列表左侧取出 |
| rpush | rpush key v1 v2 v3 ... | 从右侧插入列表 |
| rpop | rpop key | 从列表右侧取出 |
| lpushx | lpushx key v1 v2 v3 ... | 当列表非空时,从左侧插入列表 |
| rpushx | rpushx key v1 v2 v3 ... | 当列表非空时,从右侧插入列表 |
| blpop | blpop key timeout | 从列表左侧取出,当列表为空时阻塞,最大阻塞时间 timeout 秒 |
| brpop | brpop key timeout | 从列表右侧取出,当列表为空时阻塞,最大阻塞时间 timeout 秒 |
| llen | llen key | 获取列表中元素个数 |
| lindex | lindex key index | 获得列表中下标为 index 的元素 |
| lrange | lrange key start end | 返回列表中指定区间的元素 |
| lrem | lrem key count value | 移除列表中与参数 value 相等的元素,根据 count 决定删除的顺序及数量 |
| lset | lset key index value | 将列表 index 位置的元素设置成 value 的值 |
| ltrim | ltrim key start end | 对列表进行修剪,只保留 start 到 end 区间 |
| rpoplpush | rpoplpush key1 key2 | 从 key1 列表右侧弹出并插入到 key2 列表左侧 |
| brpoplpush | brpoplpush key1 key2 timeout | 从 key1 列表右侧弹出并插入到 key2 列表左侧,最大阻塞时间 timeout 秒 |
| linsert | linsert key BEFORE pivot value | 将值 value 插入到列表 key 当中,位于值 pivot 之前或之后 |
# 2.2 应用场景
- 作为栈或队列使用
- 可用于各种列表,比如用户列表、商品列表、评论列表等
# 三、Set(集合)
Set 集合类型中的元素是无序的、唯一的。
Set 的最大成员数为 ,约 40 亿个。
# 3.1 常见操作命令
| 命令 | 使用方法 | 说明 |
|---|---|---|
| sadd | sadd key mem1 mem2 ... | 为集合添加新成员 |
| srem | srem key mem1 mem2 ... | 删除集合中指定成员 |
| smembers | smembers key | 获得集合中所有元素 |
| spop | spop key | 返回集合中一个随机元素,并将该元素删除 |
| srandmember | srandmember key | 返回集合中一个随机元素,不会删除该元素 |
| scard | scard key | 获得集合中元素的数量 |
| sismember | sismember key member | 判断元素是否在集合内 |
| sinter | sinter key1 key2 key3 | 求多集合的交集 |
| sdiff | sdiff key1 key2 key3 | 求多集合的差集 |
| sunion | sunion key1 key2 key3 | 求多集合的并集 |
# 3.2 应用场景
适用于不能重复的且不需要顺序的数据结构,如:通过 spop 随机抽奖。
# 四、Sorted Set(有序集合)
SortedSet 有序集合类型中的元素是无序的、唯一的。
每个元素关联一个分数(score),可按分数排序,分数可重复。
# 4.1 常见操作命令
| 命令 | 使用方法 | 说明 |
|---|---|---|
| zadd | zadd key score1 mem1 score2 mem2 ... | 为有序集合添加新成员 |
| zrem | zrem key mem1 mem2 ... | 删除有序集合中指定成员 |
| zcard | zcard key | 获得有序集合中的元素数量 |
| zcount | zcount key min max | 返回集合中指定区间的元素数量 |
| zincrby | zincrby key increment member | 在集合的 member 分值上加 increment |
| zscore | zscore key member | 获得集合中 member 的分值 |
| zrank | zrank key member | 获得集合中 member 的排名(分值递增) |
| zrevrank | zrevrank key member | 获得集合中 member 的排名(分值递减) |
| zrange | zrange key start end | 获得集合中指定区间的成员(分值递增) |
| zrevrange | zrevrange key start end | 获得集合中指定区间的成员(分值递增) |
# 4.2 应用场景
由于可以按照分值排序,所以适用于各种排行榜。比如:点击排行榜、销量排行榜、关注排行榜等。
# 五、Hash(散列表)
Hash 是一个 string 类型的 field 和 value 的映射表,它提供了字段和字段值的映射。
每个 Hash 的最大成员数为 ,约 40 亿个。
# 5.1 常见操作命令
| 命令 | 使用方法 | 说明 |
|---|---|---|
| hset | hset key field value | 赋值,不区别新增或修改 |
| hmset | hmset key field1 value1 field2 value2 | 批量赋值 |
| hsetnx | hsetnx key field value | 赋值,如果 filed 存在则不操作 |
| hexists | hexists key filed | 查看某个 field 是否存在 |
| hget | hget key field | 获取一个字段值 |
| hmget | hmget key field1 field2 ... | 获取多个字段值 |
| hgetall | hgetall key | 获取整个散列表 |
| hdel | hdel key field1 field2 ... | 删除指定字段 |
| hincrby | hincrby key field increment | 指定字段自增 increment |
| hlen | hlen key | 获得字段数量 |
# 5.2 应用场景
- 对象的存储
- 表数据的映射
# 六、BitMap(位图)
Bitmap 位图是进行位操作的,通过一个 bit 位来表示某个元素对应的值或者状态。
Bitmap 本身会极大的节省储存空间。
# 6.1 常见操作命令
| 命令 | 使用方法 | 说明 |
| setbit | setbit key offset value | 设置 key 在 offset 处的 bit 值 0/1 |
| getbit | getbit key offset | 获得 key 在 offset 处的 bit 值 |
| bitcount | bitcount key | 获得 key 的 bit 位为 1 的个数 |
| bitpos | bitpos key value | 返回第一个被设置为 value 值的索引值 |
| bitop | bitop and destkey k1 k2 k3 ... | 对多个 key 进行逻辑与运算后存入 destkey 中 |
| bitop or destkey k1 k2 k3 ... | 对多个 key 进行逻辑或运算后存入 destkey 中 | |
| bitop xor destkey k1 k2 k3 ... | 对多个 key 进行逻辑异或运算后存入 destkey 中 | |
| bitop not destkey k1 k2 k3 ... | 对多个 key 进行逻辑非运算后存入 destkey 中 |
# 6.2 应用场景
- 用户每月签到:用户 ID 为 Key,日期作为偏移量,1 表示签到
- 统计活跃用户:日期为 Key,用户 ID 作为偏移量,1 表示活跃
- 查询用户在线状态:日期为 Key,用户 ID 作为偏移量,1 表示在线
# 七、Geo(地理位置)
Geo 是 Redis 用来处理位置信息的。
GeoHash
为了能高效地对经纬度进行比较,Redis 采用了业界广泛使用的 GeoHash 编码方法,这个方法的基本原理就是“二分区间,区间编码”。
1. 单独编码
对于一个地理位置信息来说,它的经度范围是 。GeoHash 编码会把一个经度值编码成一个 N 位的二进制值,我们来对经度范围 做 N 次的二分区操作,其中 N 可以自定义。我们用 0 表示落在左分区,用 1 表示落在右分区,这样一来,我们就可以得到一个 N 位的二进制数字。
2. 编码合并
当一组经纬度值都编完码后,我们再把它们的各自编码值组合在一起,组合的规则是:最终编码值的偶数位上依次是经度的编码值,奇数位上依次是纬度的编码值,其中,偶数位从 0 开始,奇数位从 1 开始,如下图所示。
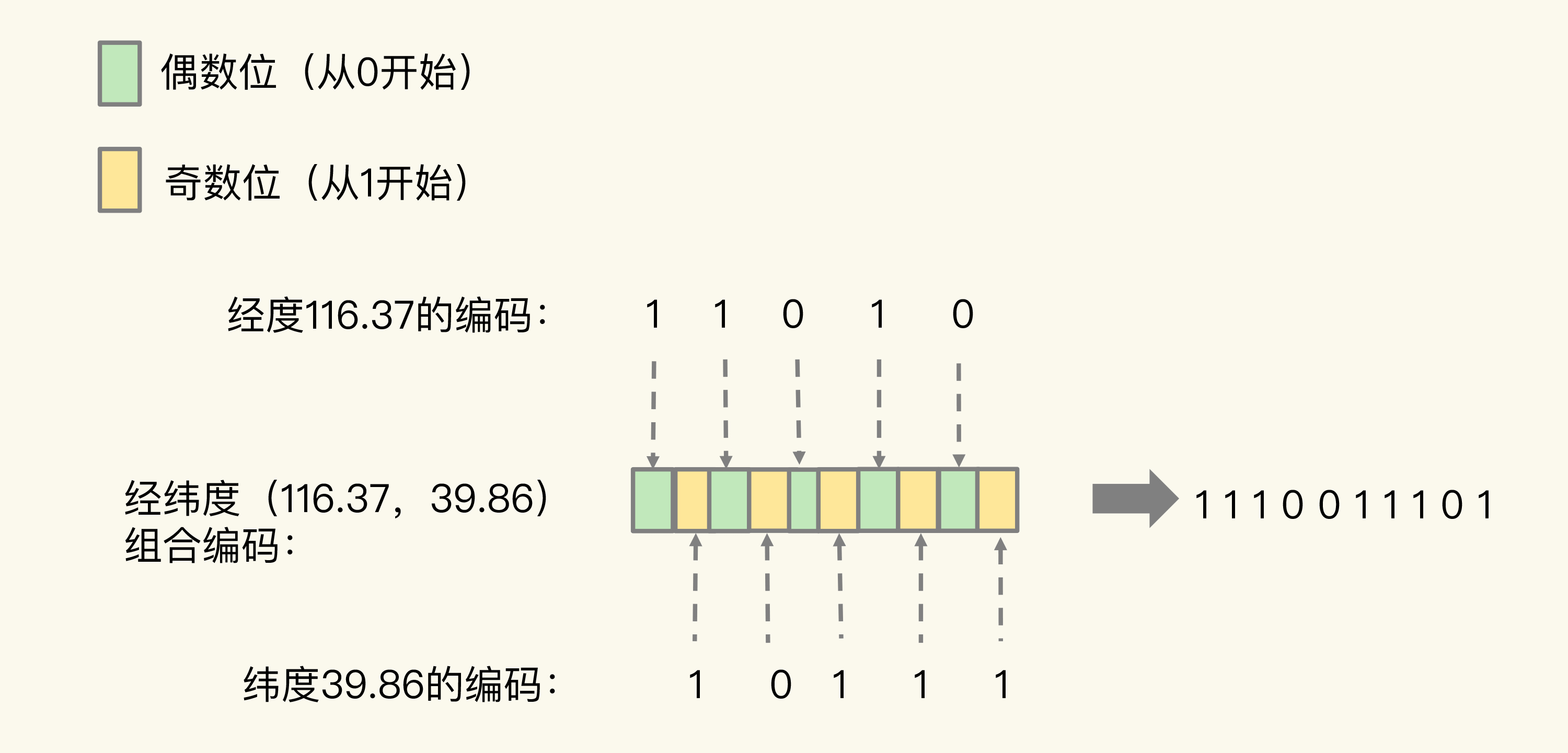
用了 GeoHash 编码后,原来无法用一个权重分数表示的一组经纬度(116.37,39.86)就可以用 1110011101 这一个值来表示,就可以保存为 Sorted Set 的权重分数了。
通过上面的合并规则可以看出,这个规则最终生成的就是 Z 阶曲线,如下图:
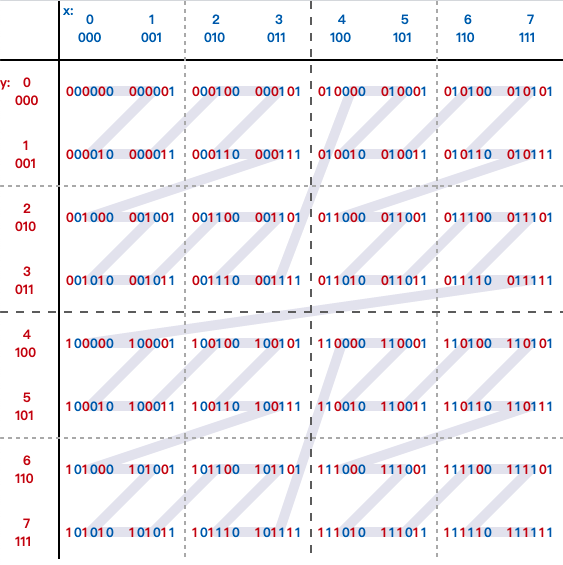
可以看到,有的编码值虽然在大小上接近,但实际对应的方格却距离比较远。所以,为了避免查询不准确问题,我们可以同时查询给定经纬度所在的方格周围的 4 个或 8 个方格。
# 7.1 常见操作命令
| 命令 | 使用方法 | 说明 |
|---|---|---|
| geoadd | geoadd key 经度1 纬度1 mem1 经度2 纬度2 mem2 ... | 添加地理坐标 |
| geohash | geohash key mem1 mem2 ... | 返回标准的 GeoHash 串 |
| geopos | geopos key mem1 mem2 ... | 返回成员经纬度 |
| geodist | geodist key mem1 mem2 距离单位 | 计算成员间距离 |
| georadiusbymember | georadiusbymember key 成员 距离 单位 count 数量 asc[desc] | 根据成员查找附近的成员 |
# 7.2 应用场景
- 记录地理位置
- 计算距离
- 查找“附近的人”
# 八、Stream(数据流)
Stream 是 Redis 5.0 后新增的数据结构,用于可持久化的消息队列。
它几乎满足了消息队列具备的全部内容,包括:
- 消息 ID 的序列化生成
- 消息遍历
- 消息的阻塞和非阻塞读取
- 消息的分组消费
- 未完成消息的处理
- 消息队列监控
每个 Stream 都有唯一的名称,它就是 Redis 的 Key,首次使用 xadd 指令追加消息时自动创建。
# 8.1 常见操作命令
| 命令 | 使用方法 | 说明 |
| xadd | xadd key id/<\*> field1 value1 ... | 将消息追加到队列 key 中,* 表示自动生成 id |
| xread | xread [COUNT] [MS] STREAMS key ... id ... | 从(多个)消息队列中读取指定数量消息 |
| xrange | xrange key start end [COUNT] | 读取队列中给定 id 范围的消息(正序) |
| xrevrange | xrevrange key start end [COUNT] | 读取队列中给定 id 范围的消息(逆序) |
| xdel | xdel key id | 删除队列的消息 |
| xgroup | xgroup create key group_name id | 创建一个新的消费组 |
| xgroup destory key group_name | 删除指定消费组 | |
| xgroup delconsumer key group_name cname | 删除指定消费组中的某个消费者 | |
| xgroup setid key id | 为消费者组设置新的最后传递的消息 id | |
| xreadgroup | xreadgroup group group_name consumer streams key | 在消费组中创建消费者并消费数据 |
# 8.2 应用场景
消费队列
# 九、HyperLogLog(基数统计)
基数统计就是指统计一个集合中不重复的元素个数。
HyperLogLog 是一种用于统计基数的数据集合类型,它的最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。
在 Redis 中,每个 HyperLogLog 只需要花费 12 KB 内存,就可以计算接近 个元素的基数。相比于元素越多就越耗费内存的 Set 和 Hash 类型,HyperLogLog 非常节省空间。
注意
HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 。
# 9.1 常见操作命令
| 命令 | 使用方法 | 说明 |
|---|---|---|
| pfadd | pfadd key v1 v2 ... | 添加元素 |
| pfcount | pfcount key | 统计 HyperLogLog 中元素数量(近似基数) |
| pfmerge | pfmerge destkey k1 k2 ... | 将多个 HyperLogLog 合并至 destkey |
# 9.2 应用场景
用于大数据量的非精确统计,如 PV、UV 数统计。