物理内存管理:连续内存分配
# 一、地址空间和地址生成
# 1.1 地址空间的定义
物理地址空间:硬件支持的地址空间,起始地址 0,直到 。
逻辑地址空间:在 CPU 运行的进程看到的地址,起始地址 0,直到 。
# 1.2 地址生成
逻辑地址生成
下图是逻辑地址生成的一个例子。
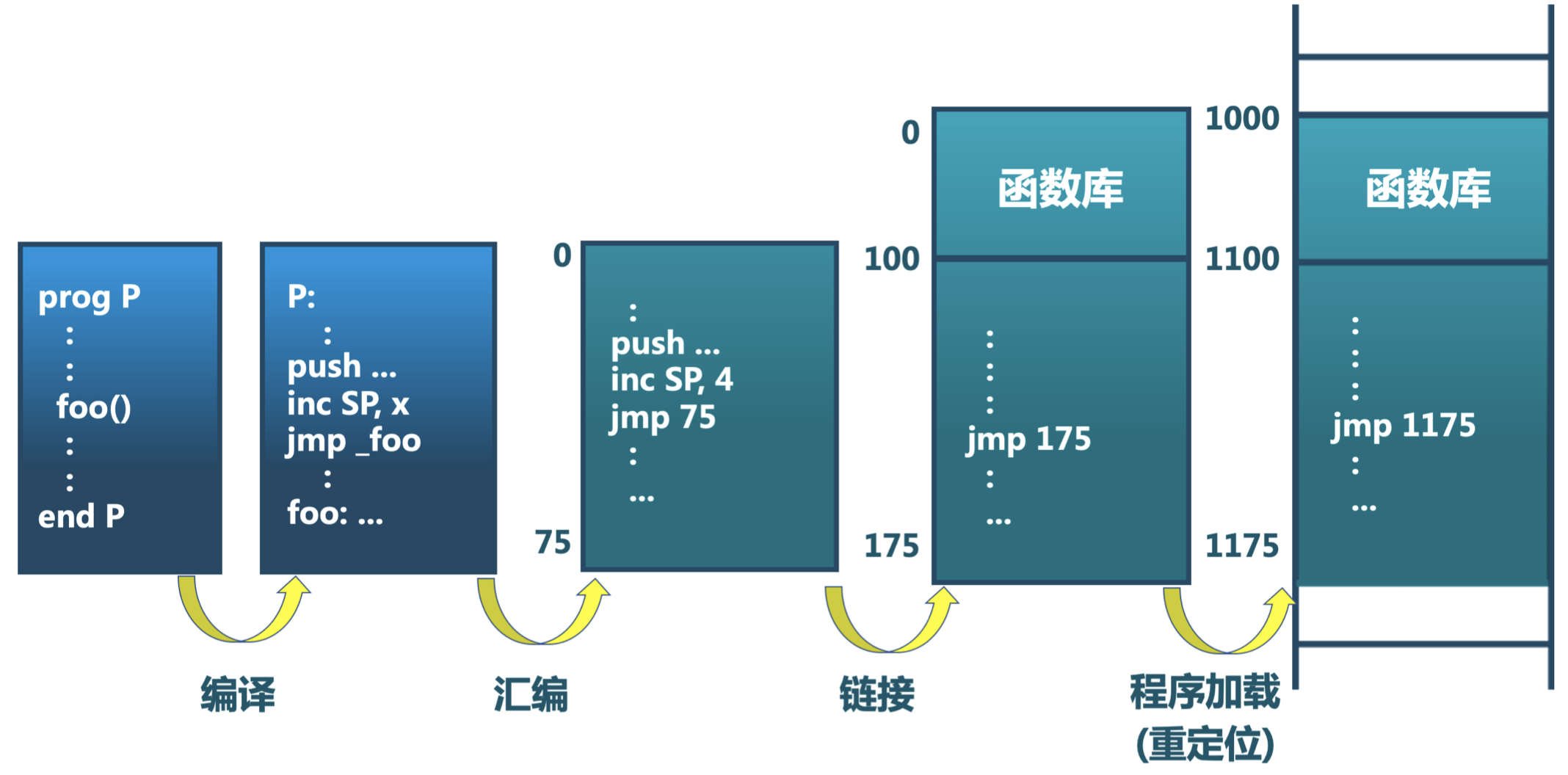
- 首先我们在程序源码中定义了一个函数
foo(),此时是不涉及地址的; - 之后通过编译,将源代码转换成 CPU 能识别的指令(汇编码),如函数调用为
jmp _foo,此时用的仍然是符号名字; - 接下来再进行汇编操作,得到二进制代码,此时将符号名转换为初步的逻辑地址,这是机器能实际运行的指令;
- 下面为了得到多模块调用时的其他模块的地址,需要进行链接操作,逻辑地址会发生偏移,得到一个线性的序列;
- 最后通过程序加载(重定位)将其转换为实际的逻辑地址。
地址生成时机和限制
- 编译时
- 假设起始地址已知
- 如果起始地址改变,必须重新编译
- 加载时
- 如编译时起始位置未知,编译器需生成可重定位的代码(relocatable code)
- 加载时,生成绝对地址
- 执行时
- 执行时代码可移动
- 需地址转换(映射)硬件支持
地址生成过程
操作系统通过建立逻辑地址 LA 和物理地址 PA 的映射,实现地址的转换,下面是地址生成过程的示意图。
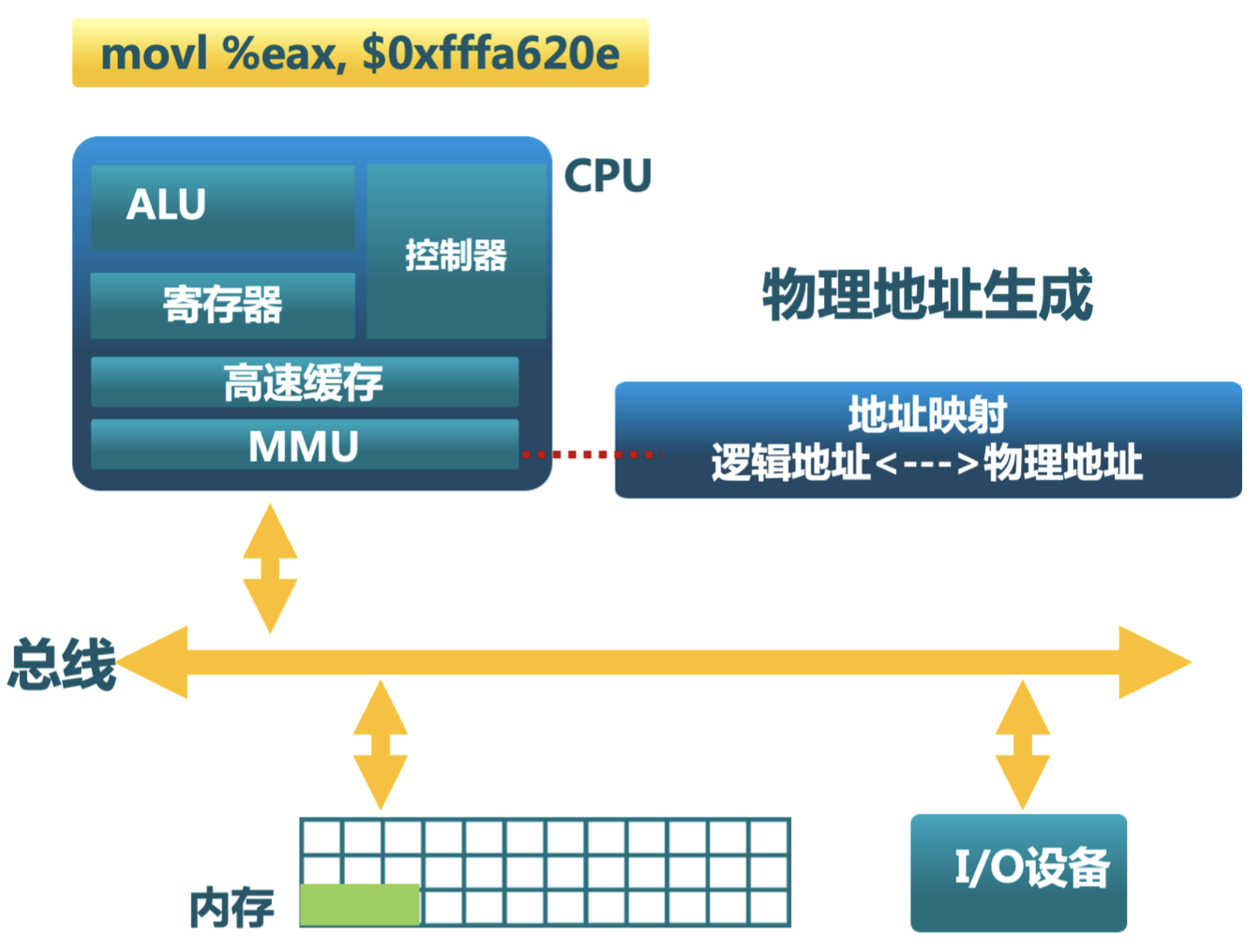
- CPU
- ALU:需要逻辑地址的内存内容
- MMU:进行逻辑地址和物理地址的转换
- CPU 控制逻辑:给总线发送物理地址请求
- 内存
- 读操作:发送物理地址的内容给 CPU
- 写操作:接收 CPU 的数据到物理地址
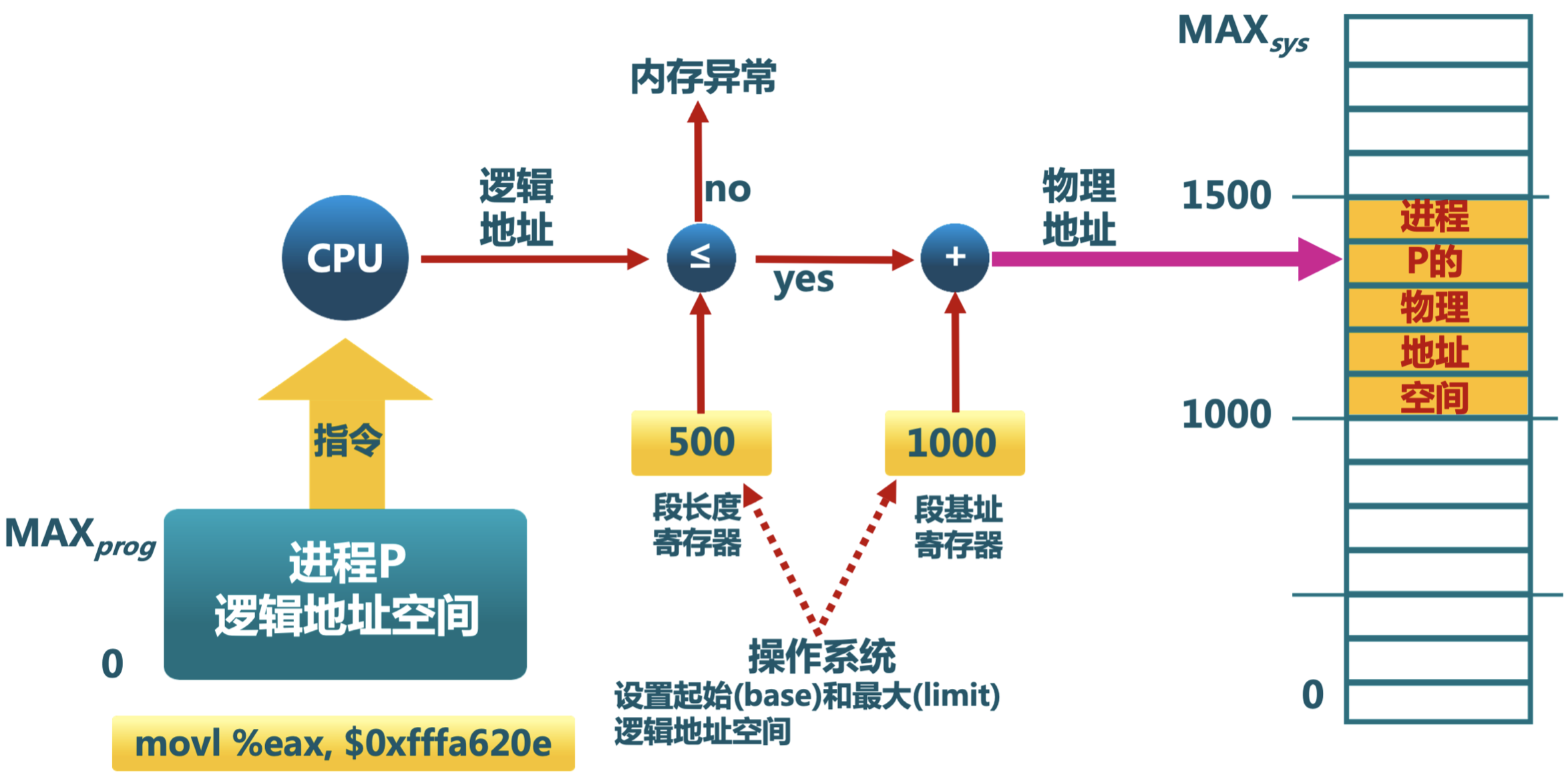
# 1.3 地址检查
# 二、连续内存分配
连续内存分配是指给进程分配一块不小于指定大小的连续的物理内存区域。
# 2.1 内存碎片
内存碎片是指不能被利用的空闲内存,根据生成方式可分为以下两种:
- 外部碎片:分配单元之间的未被使用的内存
- 内部碎片:分配单元内部的未被使用的内存,取决于分配单元大小是否要取整()
# 2.2 动态分区分配
动态分区分配是指当程序被加载执行时,分配一个进程指定大小可变的分区(块、内存块),其中分区的地址是连续的。
为了实现动态分区分配,操作系统需要维护两个数据结构,分别是:
- 所有进程的已分配分区,记录哪些分区已分配,分配给了哪个进程;
- 空闲分区(Empty-blocks),记录空闲分区的位置和大小。
分配算法:最先匹配(First Fit Allocation)策略
思路:分配 n 个字节,使用第一个可用空间不小于 n 的空闲块。
原理 & 实现:
- 空闲分区列表按地址顺序排序
- 分配过程中,搜索第一个合适的分区
- 释放分区时,检查是否可与邻近的空闲分区合并
优点:
- 实现简单
- 在高地址空间有大块的空闲分区
缺点:
- 会生成较多的外部碎片
- 分配大块分区时较慢
分配算法:最佳匹配(Best Fit Allocation)策略
思路:分配 n 个字节,查找并使用不小于 n 的最小空闲块。
原理 & 实现:
- 空闲分区列表按照有小到大排序
- 分配时,查找第一个合适的分区
- 释放时,查找并合并邻近的空闲分区(如果存在,比较耗时),调整空闲分区列表顺序
优点:
- 实现相对简单
- 大部分分配的尺寸较小时,效果很好
- 可避免大的空闲分区被拆分
- 可减小外部碎片的大小
缺点:
- 会产生外部碎片
- 释放分区速度较慢
- 容易产生很多无用的小碎片
分配算法:最差匹配(Worst Fit Allocation)策略
思路:分配 n 个字节,查找并使用不小于 n 的最大空闲块。
原理 & 实现:
- 空闲分区列表按照有大到小排序
- 分配时,查找第一个合适的分区
- 释放时,查找并合并邻近的空闲分区(如果存在,比较耗时),调整空闲分区列表顺序
优点:
- 中等大小的分配较多时,效果最好
- 避免出现太多的小碎片
缺点:
- 会产生外部碎片
- 释放分区速度较慢
- 容易破坏大的空闲分区,因此后续难以分配大的分区
# 2.3 碎片整理
碎片整理是通过调整进程占用的分区位置来减少或避免分区碎片的一种做法。
紧凑(compaction)
原理:通过移动分配给进程的内存分区,以合并外部碎片。
条件:所有的应用程序可动态重定位。
需要解决的问题:
- 什么时候移动?
- 开销?
分区对换(swap in/out)
原理:通过抢占并回收处于等待状态进程的分区,以增大可用内存空间。
# 三、伙伴系统
伙伴系统(Buddy System)比较好地折中了分配和回收过程当中合并和分配块的位置、碎片的问题。
- 整个可分配的分区大小为
- 需要的分区大小为 时,把整个块分配给该进程
- 若 ,将大小为 的当前空闲分区划分成两个大小为 的空闲分区;
- 重复划分过程,直到 ,并把一个空闲分区分配给该进程。
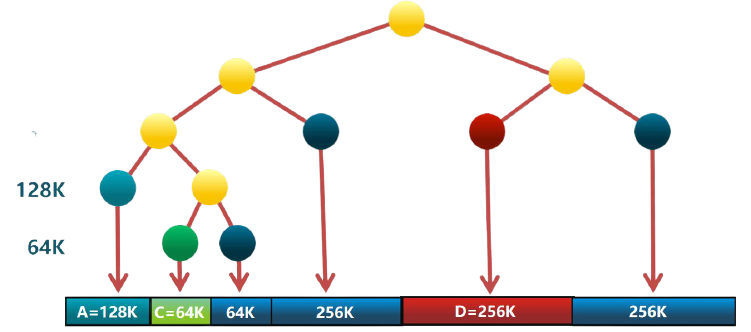
下面是一个伙伴系统内存分配与回收的示意图:

# 3.1 数据结构
- 空闲块按大小和起始地址组织成二维数组
- 初始状态:只有一个大小为 的空闲块
# 3.2 分配过程
- 由小到大在空闲块数组中找最小的可用空闲块
- 如空闲块过大,对可用空闲块进行二等分,直到得到合适的可用空闲块
# 3.3 释放过程
- 把释放的块放入空闲块数组
- 合并满足合并条件的空闲块
# 3.4 合并条件
- 大小相同为
- 地址相邻
- 起始地址较小的块的起始地址必须是 的倍数
合并示意图如下所示:
# 四、SLAB 分配器
# 4.1 需求来源
由于 Buddy 分配内存的最小单位是一页,通常情况下,一页的大小为 4k,那么当我们申请的内存空间远小于 4k 时,采用 Buddy 分配就会产生很大的内存碎片,这样的利用效率是很低的,因此创建了 SLAB 分配器来处理小内存分配请求。
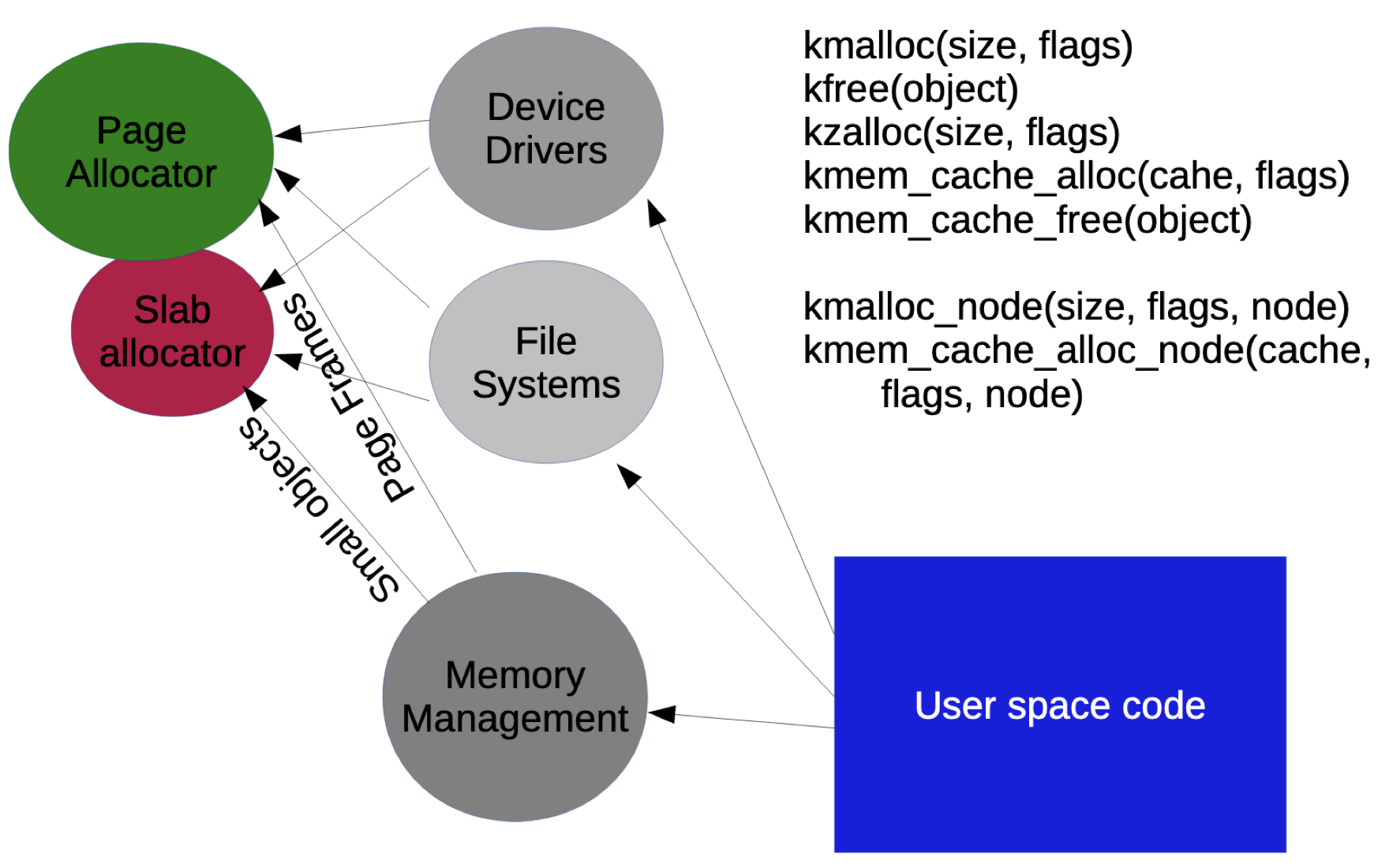
由上图可以看到,通过系统调用,应用程序可能会有各种尺度的内存分配请求,当内核拿到请求后,根据请求内存的大小,选择不同尺度的分配器,从而提高内存利用率。
# 4.2 SLAB 分配器
SLAB 分配器源于 Solaris 2.4 的分配算法,工作于内存物理页分配算法之上,管理特定大小对象的缓存,进行快速高效的物理内存分配。
想解决的问题
- 内核对象远小于页的大小
- 内核对象会被频繁的申请和释放
- 内核对象初始化时间超过分配和释放内存总时间
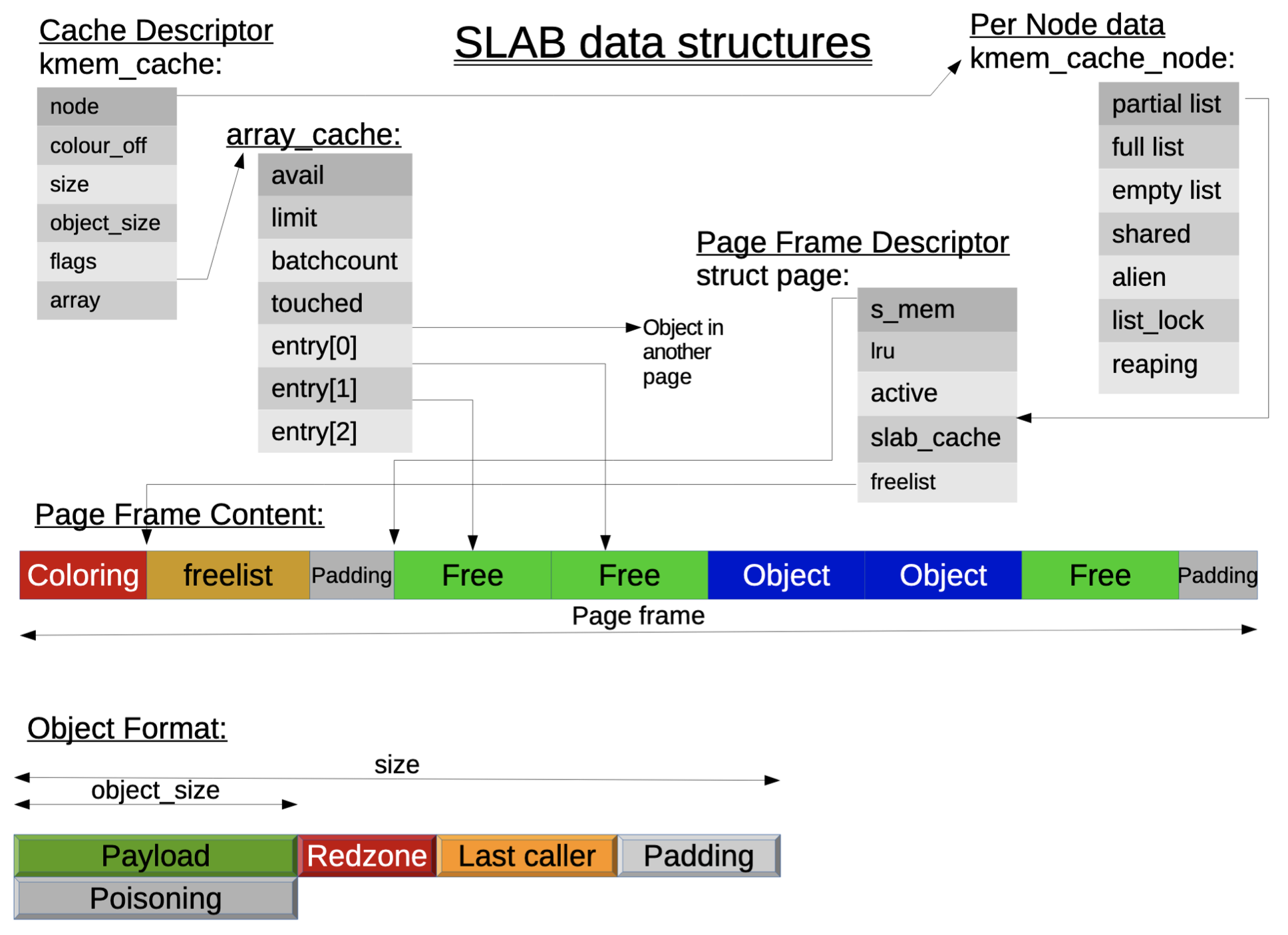
SLAB 分配器的特征
- 为每种使用的内核对象建立单独的缓冲区
- 按对象大小分组
- 两种 SLAB 对象状态:已分配或空闲
- 三类缓冲区队列:Full、Partial、Empty
- 优先从 Partial 队列中分配对象
- 缓冲区为每个处理器维护一个本地缓存
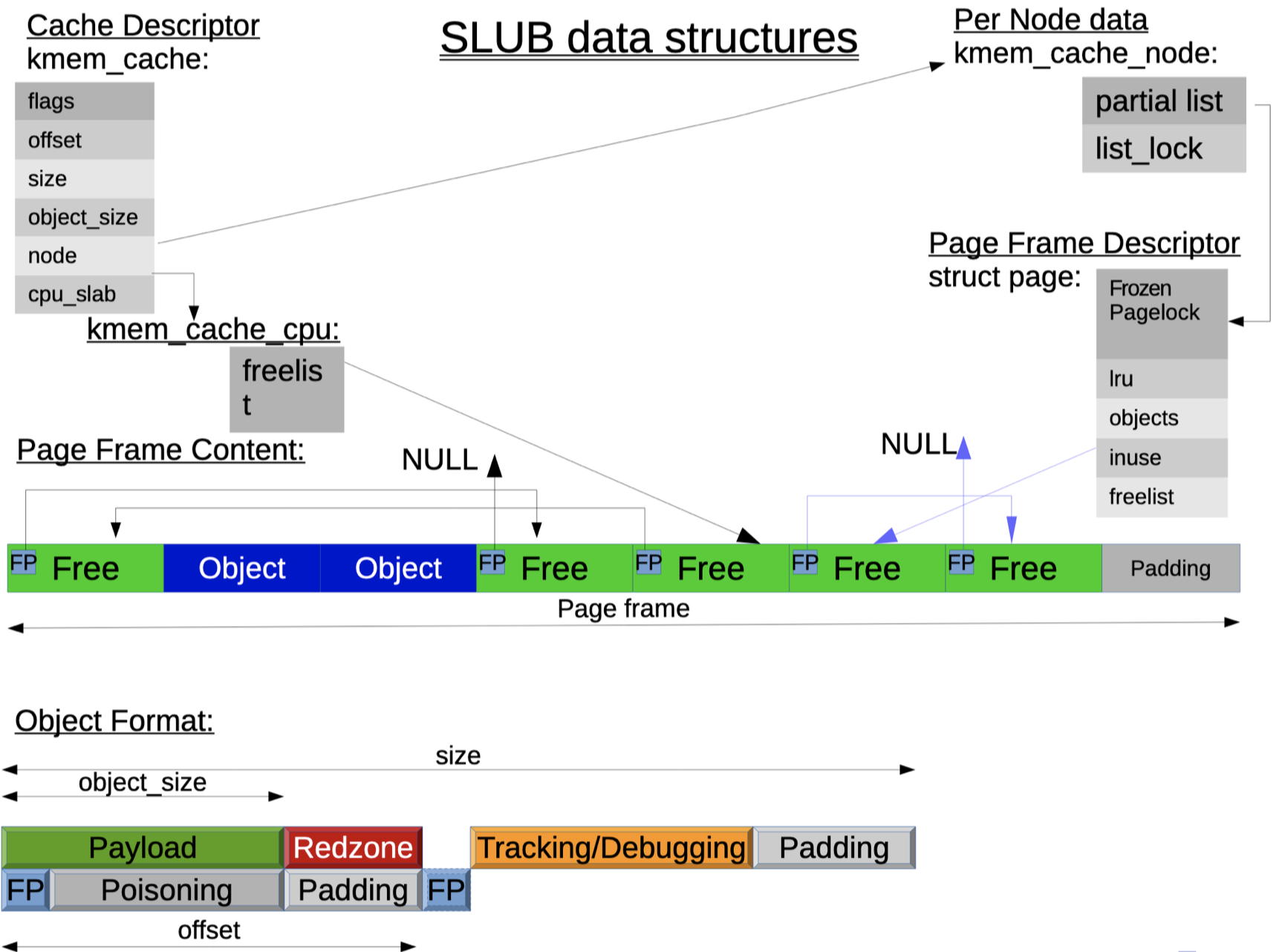
SLAB 分配器的数据结构
# 4.5 SLOB 分配器
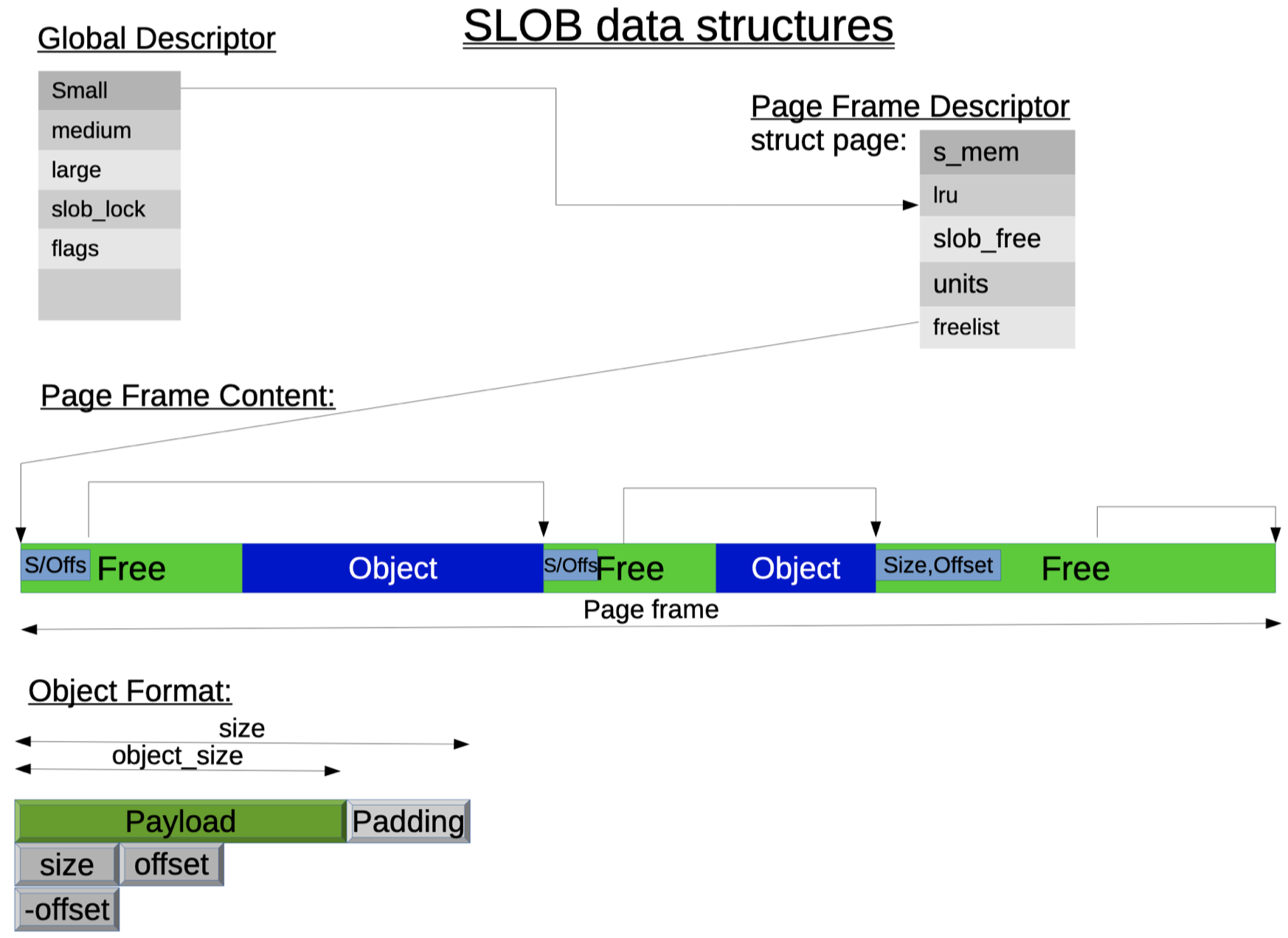
SLOB 分配器是针对嵌入式系统的 SLAB 简化版本,不同点如下所示:
- 没有本地 CPU 高速缓存和本地节点的概念
- 只存在三个全局 partial free 链表
- 链表按对象大小来划分
SLOB 分配器的数据结构
# 4.6 SLUB 分配器
目标:简化设计理念
思路:
- 简化 SLAB 的结构:取消了大量的队列和相关开销
- 一个 SLAB 是一组一个或多个页面,封装了固定大小的对象,内部没有元数据
- 将元数据存储在页面相关的页结构
- 没有单独的 Empty SLAB 队列
SLUB 分配器的数据结构