深入理解 Mutex
说明:本文分析的 Go 版本为 1.16。
# 一、锁的实现模式
# 1.1 Barging 模式
这种模式是为了提高吞吐量,当锁被释放时,它会唤醒第一个等待者,并将锁交给第一个传入的请求或这个被唤醒的等待者。

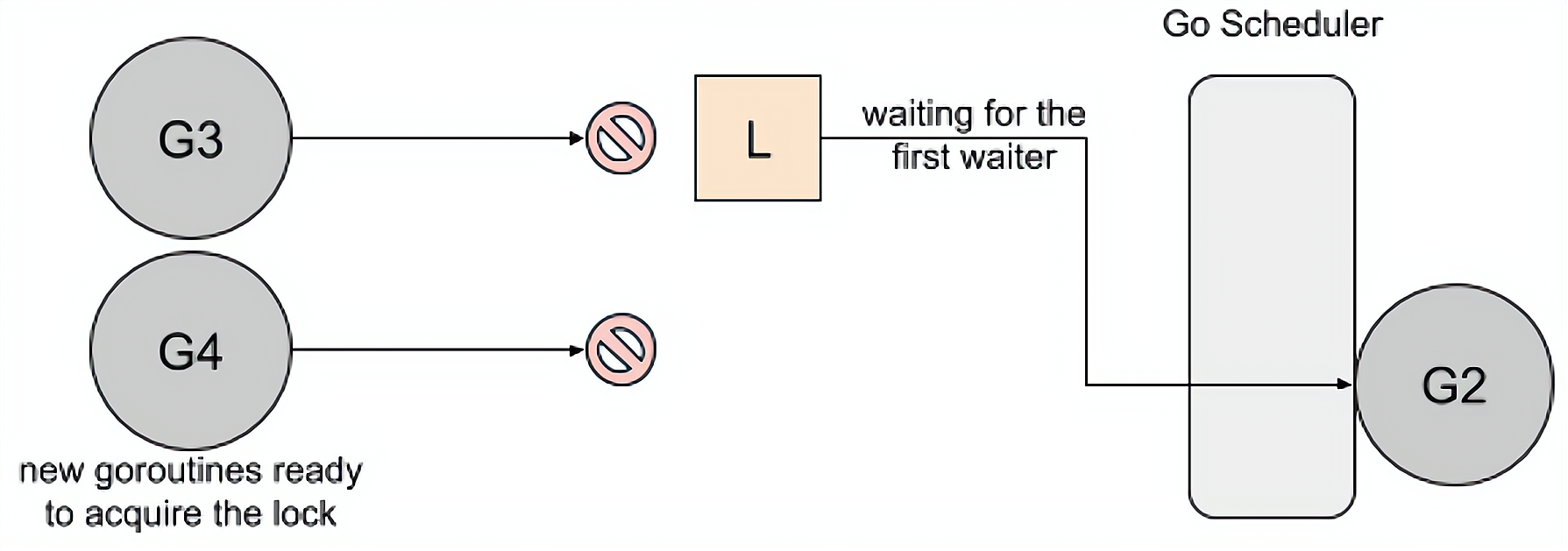
# 1.2 Handoff 模式
当锁释放时候,锁会一直持有直到第一个等待者准备好获取锁。它降低了吞吐量,因为锁被持有,即使另一个 goroutine 准备获取它。
- 优点:可以解决公平性的问题;
- 因为在 Barging 模式下可能会存在被唤醒的 goroutine 永远也获取不到锁(Starvation,锁饥饿)的情况,毕竟一直在 CPU 上跑着的 goroutine 没有上下文切换会更快一些;
- 缺点:性能会相对差一些。
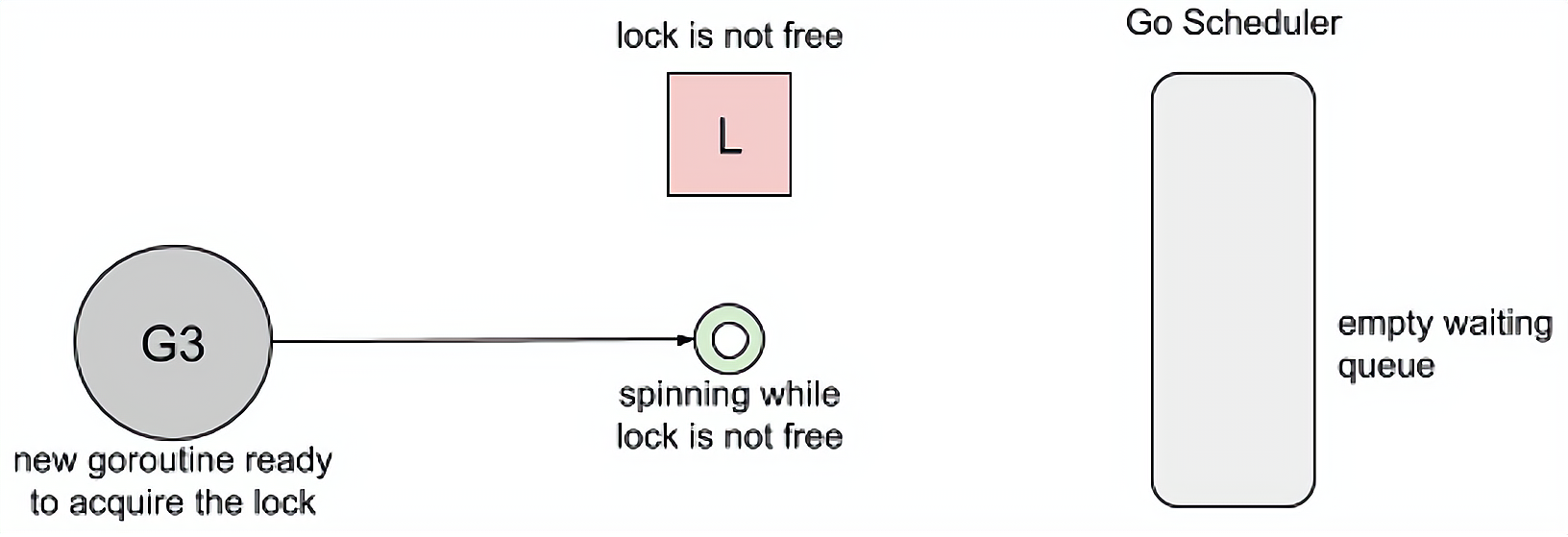
# 1.3 Spinning 模式
自旋在 等待队列为空 或者 应用程序重度使用锁 时效果不错。Parking 和 Unparking goroutines 有不低的性能成本开销,相比自旋来说要慢得多。但是自旋是有成本的,所以在 Go 的实现中进入自旋的条件十分的苛刻。
# 二、Mutex(互斥锁)
# 2.1 使用示例
使用 sync.Mutex 可以解决 Go 数据竞争中的例子 的运行结果不确定的问题,修改代码如下:
package main
import (
"fmt"
"sync"
)
var (
wg sync.WaitGroup
mu sync.Mutex
counter int
)
func main() {
for i := 0; i < 1000; i++ {
wg.Add(1)
go routine()
}
wg.Wait()
fmt.Printf("Final Counter: %d\n", counter)
}
func routine() {
mu.Lock()
value := counter
value++
counter = value
mu.Unlock()
wg.Done()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
运行结果如下:
Final Counter: 1000
这里使用互斥锁来保护我们临界区的数据,锁的使用非常简单,但还是有几个需要注意的点:
- 锁的范围要尽量的小,不要搞很多大锁;
- 用锁一定要解锁,小心产生死锁;
简而言之,最晚加锁,最早释放。
# 2.2 源码分析:Mutex 结构
Go 语言的 sync.Mutex 由两个字段 state 和 sema 组成。其中 state 表示当前互斥锁的状态,而 sema 是用于控制锁状态的信号量。
type Mutex struct {
state int32
sema uint32
}
2
3
4
# 2.3 源码分析:Mutex 状态
互斥锁的状态比较复杂,如下图所示,最低三位分别表示 mutexLocked、mutexWoken 和 mutexStarving,剩下的位置用来表示当前有多少个 goroutine 在等待互斥锁的释放:

在默认情况下,互斥锁的所有状态位都是 0,int32 中的不同位分别表示了不同的状态:
mutexLocked:表示是否处于锁定状态;mutexWoken:表示是否处于唤醒状态;mutexStarving:表示是否处于饥饿状态;waiterCount:当前互斥锁上等待的 goroutine 个数。
# 2.4 源码分析:正常模式和饥饿模式
sync.Mutex 有两种模式:正常模式和饥饿模式。
在正常模式下,锁的等待者会按照先进先出的顺序获取锁。但是刚被唤起的 goroutine 与新创建的 goroutine 竞争时,大概率会获取不到锁,为了减少这种情况的出现,一旦 goroutine 超过 1ms 没有获取到锁,它就会将当前互斥锁切换饥饿模式(即触发 Handoff),防止部分 goroutine 被『饿死』。
饥饿模式是在 Go 语言在 1.9 中引入的优化,其目的是 保证互斥锁的公平性。
在饥饿模式中,互斥锁会直接交给等待队列最前面的 goroutine。新的 goroutine 在该状态下不能获取锁、也不会进入自旋状态,它们只会在队列的末尾等待。如果一个 goroutine 获得了互斥锁并且它在队列的末尾或者它等待的时间少于 1ms,那么当前的互斥锁就会切换回正常模式。
# 2.5 源码分析:加锁逻辑
Mutex 加锁的整体流程图如下:

下面分模块对其源码进行具体分析。
函数入口
// Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
// 原子替换锁的状态
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
当我们调用 Lock 方法的时候,会先尝试走 Fast Path,也就是如果当前互斥锁如果处于未加锁的状态,尝试加锁,只要加锁成功就直接返回;否则进入 Slow Path 尝试通过自旋(Spinnig)等方式等待锁的释放,该方法的主体是一个非常大 for 循环,这里将它分成几个部分介绍获取锁的过程:
- 判断当前 goroutine 能否进入自旋,并通过自旋等待互斥锁的释放;
- 计算互斥锁的最新状态;
- 更新互斥锁的状态并获取锁。
Slow Path:判断当前 goroutine 能否进入自旋,并通过自旋等待互斥锁的释放
func (m *Mutex) lockSlow() {
var waitStartTime int64 // 当前 goroutine 等待的时间
starving := false // 当前 goroutine 是否处于饥饿状态
awoke := false // 当前 goroutine 是否处于唤醒状态
iter := 0 // 当前 goroutine 自旋次数
old := m.state // 记录当前锁的状态
for {
// Don't spin in starvation mode, ownership is handed off to waiters
// so we won't be able to acquire the mutex anyway.
// 条件 1:锁还没有释放并且不是饥饿状态
// 条件 2:runtime_canSpin 返回 true,即还需满足自旋的条件
// 饥饿模式不进入自旋,因为饥饿模式锁的主动权给在等待队列第一个,所以进入自旋的话没有意义
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
// Active spinning makes sense.
// Try to set mutexWoken flag to inform Unlock
// to not wake other blocked goroutines.
// 条件 1:当前 groutine 没有处于唤醒状态
// 条件 2:锁没有处于 mutexWoken 唤醒状态
// 条件 3:等待的 goroutine 个数 waiterCount 不为 0
// 满足以上三种条件时,尝试 CAS 更改锁的状态为唤醒状态,并设置当前 goroutine 为唤醒状态
// 从而避免唤醒其他已经休眠的 goroutine,使当前的 goroutine 就能更快的获取到锁
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin() // 执行自旋操作
iter++
old = m.state
continue
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
自旋是一种多线程同步机制,当前的进程在进入自旋的过程中会一直保持 CPU 的占用,持续检查某个条件是否为真。在多核的 CPU 上,自旋可以避免 goroutine 的切换,使用恰当会对性能带来很大的增益,但是使用的不恰当就会拖慢整个程序,所以 goroutine 进入自旋的条件非常苛刻:
- 互斥锁只有在普通模式才能进入自旋;
runtime.sync_runtime_canSpin需要返回true:- 运行在多 CPU 的机器上;
- 当前 goroutine 为了获取该锁进入自旋的次数小于 4 次;
- 当前机器上至少存在一个正在运行的处理器 P 并且处理的运行队列为空;
一旦当前 goroutine 能够进入自旋就会调用 runtime.sync_runtime_doSpin 和 runtime.procyield 并执行 30 次的 PAUSE 指令,该指令只会占用 CPU 并消耗 CPU 时间。
TEXT runtime·procyield(SB),NOSPLIT,$0-0
MOVL cycles+0(FP), AX
again:
PAUSE
SUBL $1, AX
JNZ again
RET
2
3
4
5
6
7
说明
为什么使用 PAUSE 指令?
PAUSE 指令会告诉 CPU 我当前处于处于自旋状态,这时候 CPU 会针对性的做一些优化,并且在执行这个指令的时候 CPU 会降低自己的功耗,减少能源消耗。
点击查看 Spin 相关源码
const (
active_spin = 4
active_spin_cnt = 30
)
// Active spinning for sync.Mutex.
//go:linkname sync_runtime_canSpin sync.runtime_canSpin
//go:nosplit
func sync_runtime_canSpin(i int) bool {
// sync.Mutex is cooperative, so we are conservative with spinning.
// Spin only few times and only if running on a multicore machine and
// GOMAXPROCS>1 and there is at least one other running P and local runq is empty.
// As opposed to runtime mutex we don't do passive spinning here,
// because there can be work on global runq or on other Ps.
if i >= active_spin || ncpu <= 1 || gomaxprocs <= int32(sched.npidle+sched.nmspinning)+1 {
return false
}
if p := getg().m.p.ptr(); !runqempty(p) {
return false
}
return true
}
//go:linkname sync_runtime_doSpin sync.runtime_doSpin
//go:nosplit
func sync_runtime_doSpin() {
procyield(active_spin_cnt)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
Slow Path:计算互斥锁的最新状态
new := old
// Don't try to acquire starving mutex, new arriving goroutines must queue.
// 如果当前锁是正常模式,则尝试获取锁,也就是设置锁为 mutexLocked 状态
// 如果当前锁是饥饿模式,则严格按照 FIFO 队列排队获取,不主动去尝试获取锁
if old&mutexStarving == 0 {
new |= mutexLocked
}
// 如果当前锁是锁定状态或者处于饥饿模式,则 waiter 等待数 +1
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
// The current goroutine switches mutex to starvation mode.
// But if the mutex is currently unlocked, don't do the switch.
// Unlock expects that starving mutex has waiters, which will not
// be true in this case.
// 如果当前 goroutine 为饥饿状态,并且锁的状态是锁定状态,则设置锁为饥饿状态
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
// 如果当前 goroutine 是唤醒状态,需要清除锁的 mutexWoken 位
if awoke {
// The goroutine has been woken from sleep,
// so we need to reset the flag in either case.
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
以上锁状态的处理,可分为以下几种情况:
- 当前锁处于正常模式:
- 设置锁 Locked 位
- 设置锁 waiterCount++
- 当前锁处于饥饿模式:
- 设置锁 waiterCount++
- 当前 goroutine 处于饥饿状态:
- 如果锁 Locked,则设置锁 Starving 位
- 当前 goroutine 处于唤醒状态:
- 清除锁 Woken 位
Slow Path:更新互斥锁的状态并获取锁
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 如果 old 锁不是饥饿状态并且未被锁定,说明当前 goroutine 已经得到了锁,直接退出
if old&(mutexLocked|mutexStarving) == 0 {
break // locked the mutex with CAS
}
// If we were already waiting before, queue at the front of the queue.
queueLifo := waitStartTime != 0 // 首次循环 queueLifo 必为 false,表示是新的 goroutine
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
// 信号量获取,如果是新的 goroutine,加入队列尾部;否则加入队列头部
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// 执行到此处代表当前 goroutine 已经被唤醒,继续抢锁时先判断是否需要进入饥饿模式
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs // 等待超过 1ms 就进入饥饿模式
old = m.state
// 如果本来就处于饥饿模式
if old&mutexStarving != 0 {
// If this goroutine was woken and mutex is in starvation mode,
// ownership was handed off to us but mutex is in somewhat
// inconsistent state: mutexLocked is not set and we are still
// accounted as waiter. Fix that.
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
// 此时饥饿模式下被唤醒,那么一定能上锁成功。因为 Unlock 保证饥饿模式下只唤醒 park 状态的 goroutine
delta := int32(mutexLocked - 1<<mutexWaiterShift)
// 如果当前 goroutine 不是饥饿状态,或者为最后一个等待者,则将锁退出饥饿模式
if !starving || old>>mutexWaiterShift == 1 {
// Exit starvation mode.
// Critical to do it here and consider wait time.
// Starvation mode is so inefficient, that two goroutines
// can go lock-step infinitely once they switch mutex
// to starvation mode.
delta -= mutexStarving
}
// 获得锁退出
atomic.AddInt32(&m.state, delta)
break
}
// 走到这里,不是饥饿模式,重新发起抢锁竞争
// 正常模式下,当前 goroutine 被唤醒,自旋次数初始为 0
awoke = true
iter = 0
} else {
// CAS 失败,重新发起抢锁竞争
old = m.state
}
}
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 2.6 源码分析:解锁逻辑
// Unlock unlocks m.
// It is a run-time error if m is not locked on entry to Unlock.
//
// A locked Mutex is not associated with a particular goroutine.
// It is allowed for one goroutine to lock a Mutex and then
// arrange for another goroutine to unlock it.
// 解锁一个未锁定的 m 会报运行时错误
// 解锁没有绑定关系,可以一个 goroutine 锁定,另外一个 goroutine 解锁
func (m *Mutex) Unlock() {
if race.Enabled {
_ = m.state
race.Release(unsafe.Pointer(m))
}
// Fast path: drop lock bit.
// Fast path: 直接尝试设置 state 的值,进行解锁
new := atomic.AddInt32(&m.state, -mutexLocked)
// 如果减去了 mutexLocked 的值之后不为零就会进入 slow path,这说明有可能失败了,或者是还有其他的 goroutine 等着
if new != 0 {
// Outlined slow path to allow inlining the fast path.
// To hide unlockSlow during tracing we skip one extra frame when tracing GoUnblock.
m.unlockSlow(new)
}
}
func (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
// 判断是否处于饥饿模式
if new&mutexStarving == 0 { // 正常模式
old := new
for {
// If there are no waiters or a goroutine has already
// been woken or grabbed the lock, no need to wake anyone.
// In starvation mode ownership is directly handed off from unlocking
// goroutine to the next waiter. We are not part of this chain,
// since we did not observe mutexStarving when we unlocked the mutex above.
// So get off the way.
// 如果互斥锁不存在等待者或者互斥锁的状态位不都为 0,则直接返回,不需要唤醒其他等待者
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// Grab the right to wake someone.
// 唤醒等待者并移交锁的所有权
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else { // 饥饿模式
// Starving mode: handoff mutex ownership to the next waiter, and yield
// our time slice so that the next waiter can start to run immediately.
// Note: mutexLocked is not set, the waiter will set it after wakeup.
// But mutex is still considered locked if mutexStarving is set,
// so new coming goroutines won't acquire it.
// 将当前锁交给下一个正在尝试获取锁的等待者,等待者被唤醒后会得到锁,在这时互斥锁还不会退出饥饿状态
runtime_Semrelease(&m.sema, true, 1)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# 2.7 小结
互斥锁的加锁过程比较复杂,它涉及自旋、信号量以及调度等概念:
- 如果互斥锁处于初始化状态,会通过置位
mutexLocked加锁; - 如果互斥锁处于
mutexLocked状态并且在正常模式下工作,会进入自旋,执行 30 次 PAUSE 指令消耗 CPU 时间等待锁的释放; - 如果当前 goroutine 等待锁的时间超过了 1ms,互斥锁就会切换到饥饿模式;
- 互斥锁在正常情况下会通过
runtime.sync_runtime_SemacquireMutex将尝试获取锁的 goroutine 切换至休眠状态,等待锁的持有者唤醒; - 如果当前 goroutine 是互斥锁上的最后一个等待的协程或者等待的时间小于 1ms,那么它会将互斥锁切换回正常模式。
互斥锁的解锁过程与之相比就比较简单,其代码行数不多、逻辑清晰,也比较容易理解:
- 当互斥锁已经被解锁时,调用
sync.Mutex.Unlock会直接抛出异常; - 当互斥锁处于饥饿模式时,将锁的所有权交给队列中的下一个等待者,等待者会负责设置
mutexLocked标志位; - 当互斥锁处于普通模式时,如果没有 goroutine 等待锁的释放或者已经有被唤醒的 goroutine 获得了锁,会直接返回;在其他情况下会通过
sync.runtime_Semrelease唤醒对应的 goroutine。
# 三、RWMutex(读写锁)
sync.RWMutex 是细粒度的互斥锁,它不限制资源的并发读,但是读写、写写操作无法并行执行。
# 3.1 使用示例
大部分的业务应用都是读多写少的场景,这个时候使用读写锁的性能就会比互斥锁要好一些,例如下面的这个例子,是一个配置读写的例子,我们分别使用读写锁和互斥锁实现。
并发基准测试:
type iConfig interface {
Get() []int
Set([]int)
}
func bench(b *testing.B, c iConfig) {
b.RunParallel(func(p *testing.PB) {
for p.Next() {
c.Set([]int{100})
c.Get()
c.Get()
c.Get()
c.Set([]int{100})
c.Get()
c.Get()
}
})
}
func BenchmarkMutexConfig(b *testing.B) {
conf := &MutexConfig{data: []int{1, 2, 3}}
bench(b, conf)
}
func BenchmarkRWMutexConfig(b *testing.B) {
conf := &RWMutexConfig{data: []int{1, 2, 3}}
bench(b, conf)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
执行命令 go test -race -bench=.,运行结果如下:
goos: darwin
goarch: amd64
cpu: Intel(R) Core(TM) i5-8259U CPU @ 2.30GHz
BenchmarkMutexConfig-8 225865 5068 ns/op
BenchmarkRWMutexConfig-8 326438 3397 ns/op
PASS
可以看到首先是没有 data race 问题,其次读写锁的性能相比互斥锁会高一些。
# 3.2 源码分析:RWMutex 结构
type RWMutex struct {
w Mutex // 复用互斥锁提供的能力
writerSem uint32 // 信号量,用于写等待读
readerSem uint32 // 信号量,用于读等待写
readerCount int32 // 当前执行读的 goroutine 数量
readerWait int32 // 被写操作阻塞的准备读的 goroutine 的数量
}
2
3
4
5
6
7
# 3.3 源码分析:写锁
写操作使用 sync.RWMutex.Lock 和 sync.RWMutex.Unlock 方法,下面分别对它们的源码进行分析。
加锁
// Lock locks rw for writing.
// If the lock is already locked for reading or writing,
// Lock blocks until the lock is available.
func (rw *RWMutex) Lock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// First, resolve competition with other writers.
// 首先获取互斥锁,阻塞后续写操作
rw.w.Lock()
// Announce to readers there is a pending writer.
// 阻塞后续读操作
// 原理:将 readerCount 减去一个最大值,则其必然会变成一个小于 0 的数,
// 那么在调用读锁 RLock 方法时,将会因为 readerCount 小于 0 而阻塞住,这样也就阻塞住了新来的读请求。
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// Wait for active readers.
// 短路操作,等待所有读操作完成
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
race.Acquire(unsafe.Pointer(&rw.writerSem))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
- 获取结构体持有的 Mutex,阻塞后续的写操作;
- 通过 atomic 将 readerCount 改为负数,阻塞后续的读操作;
- 如果仍然有其他 goroutine 持有读锁,那么就调用
runtime_SemacquireMutex休眠当前的 goroutine 等待所有的读操作完成。
注意
获取写锁时会先阻塞写锁的获取,后阻塞读锁的获取,这种策略能够保证读操作不会被连续的写操作『饿死』。
解锁
// Unlock unlocks rw for writing. It is a run-time error if rw is
// not locked for writing on entry to Unlock.
//
// As with Mutexes, a locked RWMutex is not associated with a particular
// goroutine. One goroutine may RLock (Lock) a RWMutex and then
// arrange for another goroutine to RUnlock (Unlock) it.
func (rw *RWMutex) Unlock() {
if race.Enabled {
_ = rw.w.state
race.Release(unsafe.Pointer(&rw.readerSem))
race.Disable()
}
// Announce to readers there is no active writer.
// 将 readerCount 恢复为正数,释放读锁,允许接收新的读操作
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
if r >= rwmutexMaxReaders {
race.Enable()
throw("sync: Unlock of unlocked RWMutex")
}
// Unblock blocked readers, if any.
// 释放因获取读锁而陷入等待的 goroutine
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// Allow other writers to proceed.
// 释放互斥锁,接收后续写操作
rw.w.Unlock()
if race.Enabled {
race.Enable()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
- 通过 atomic 将 readerCount 恢复为正数,接收后续的读操作;
- 通过 for 循环释放所有因为获取读锁而陷入等待的 goroutine:
- 释放结构体持有的 Mutex,接收后续的写操作。
# 3.4 源码分析:读锁
读操作使用 sync.RWMutex.RLock 和 sync.RWMutex.RUnlock 方法,下面分别对它们的源码进行分析。
加锁
// RLock locks rw for reading.
//
// It should not be used for recursive read locking; a blocked Lock
// call excludes new readers from acquiring the lock. See the
// documentation on the RWMutex type.
func (rw *RWMutex) RLock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// 将 readerCount + 1,若结果为负数,陷入休眠等待锁的释放
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// A writer is pending, wait for it.
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 如果 readerCount 返回负数:其他 goroutine 获得了写锁,当前 goroutine 就会调用
runtime_SemacquireMutex陷入休眠等待锁的释放; - 如果 readerCount 返回非负数:没有 goroutine 获得写锁,当前方法会成功返回。
解锁
// RUnlock undoes a single RLock call;
// it does not affect other simultaneous readers.
// It is a run-time error if rw is not locked for reading
// on entry to RUnlock.
func (rw *RWMutex) RUnlock() {
if race.Enabled {
_ = rw.w.state
race.ReleaseMerge(unsafe.Pointer(&rw.writerSem))
race.Disable()
}
// 将 readerCount - 1,若结果为负数,说明有一个正在执行的写操作
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
// Outlined slow-path to allow the fast-path to be inlined
rw.rUnlockSlow(r)
}
if race.Enabled {
race.Enable()
}
}
func (rw *RWMutex) rUnlockSlow(r int32) {
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
race.Enable()
throw("sync: RUnlock of unlocked RWMutex")
}
// A writer is pending.
// 每个 reader 完成读操作后将 readerWait - 1
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// The last reader unblocks the writer.
// 当 readerWait 为 0 时代表 writer 等待的所有 reader 都已经完成了,可以唤醒 writer 了
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 3.5 小结
- 如果没有 writer 请求进来,则每个 reader 开始后只是将 readerCount + 1,完成后将 readerCount - 1,整个过程不阻塞,这样就做到 并发读操作之间不互斥;
- 当有 writer 请求进来时,首先通过互斥锁阻塞住新来的 writer,做到 并发写操作之间互斥;
- 然后将 readerCount 改成一个很小的值,从而阻塞住新来的 reader;
- 记录 writer 进来之前未完成的 reader 数量,等待它们都完成后再唤醒 writer,这样就做到了 并发读操作和写操作互斥;
- writer 结束后将 readerCount 置回原来的值,保证新的 reader 不会被阻塞,然后唤醒之前等待的 reader,再将互斥锁释放,使后续 writer 不会被阻塞。