Go 内存模型
# 一、忠告
如果程序中修改数据时有其他 goroutine 同时读取,那么必须 将读取串行化。为了串行化访问,请使用 channel 或其他同步原语,例如 sync 和 sync/atomic 来保护数据。
# 二、Happens Before
在一个 gouroutine 中,读和写一定是按照程序中的顺序执行的。即编译器和处理器只有在不会改变这个 goroutine 的行为时才可能修改读和写的执行顺序。由于重排,不同的 goroutine 可能会看到不同的执行顺序。例如,一个 goroutine 执行 a = 1;b = 2;,另一个 goroutine 可能看到 b 在 a 之前更新。
Go 内存模型指定了一种条件,在这种条件下,可以保证在一个 goroutine 中看到在另一个 goroutine 修改的变量的值。
# 2.1 编译器重排
首先来看一个代码片段:
X = 0
for i in range(100):
X = 1
print X
2
3
4
这段代码执行的结果是打印 100 个 1。一个聪明的编译器会分析到循环里对 X 的赋值 X = 1 是多余的,每次都要给它赋上 1,完全没必要。因此会把代码优化一下:
X = 1
for i in range(100):
print X
2
3
优化后的运行结果完全和之前的一样,完美!
但是,如果这时有另外一个线程同时干了这么一件事:
X = 0
由于这两个线程并行执行,优化前的代码运行的结果可能是这样的:11101111...。出现了 1 个 0,但在下次循环中,又会被重新赋值为 1,而且之后一直都是 1。
但是优化后的代码呢:11100000...。由于把 X = 1 这一条赋值语句给优化掉了,某个时刻 X 变成 0 之后,再也没机会变回原来的 1 了。
因此,在多核心场景下,没有办法轻易地判断两段程序是“等价”的。
可见编译器的重排也是基于运行效率考虑的,但以多线程运行时,就会出各种问题。
# 2.2 内存重排
现代 CPU 为了 “抚平” 内核、内存、硬盘之间的速度差异,搞出了各种策略,例如三级缓存等。现在有两个线程 Thread 1 和 Thread 2,如下图所示:
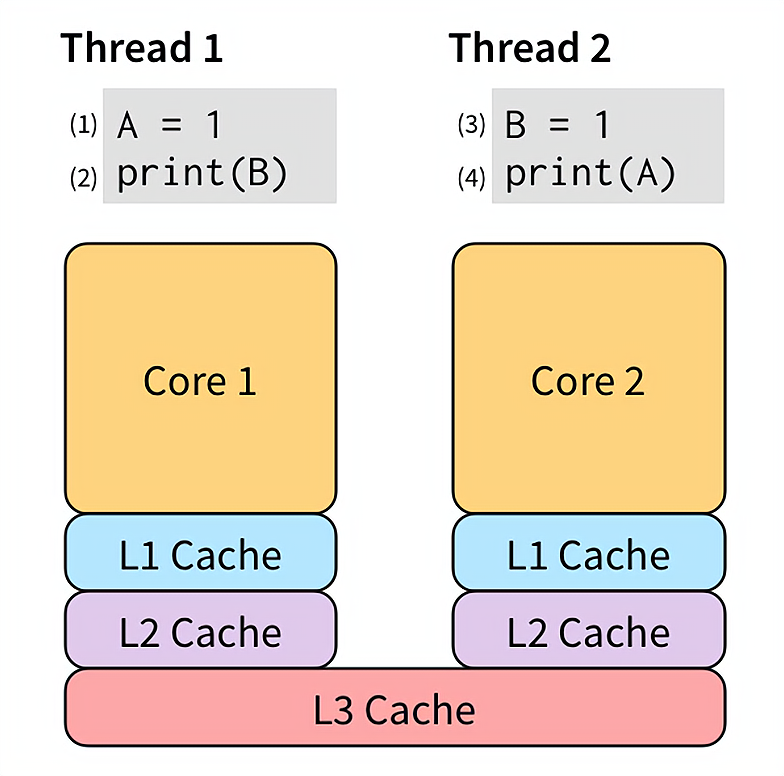
为了让 (2) 不必等待 (1) 的执行“效果”可见之后才能执行,我们可以把 (1) 的效果保存到 store buffer:

当 (1) 的“效果”写到了 store buffer 后,(2) 就可以开始执行了,不必等到 A = 1 到达 L3 cache。因为 store buffer 是在内核里完成的,所以速度非常快。在这之后的某个时刻,A = 1 会被逐级写到 L3 cache,从而被其他所有线程看到。store buffer 相当于把写的耗时隐藏了起来。
store buffer 对单线程是完美的,例如:
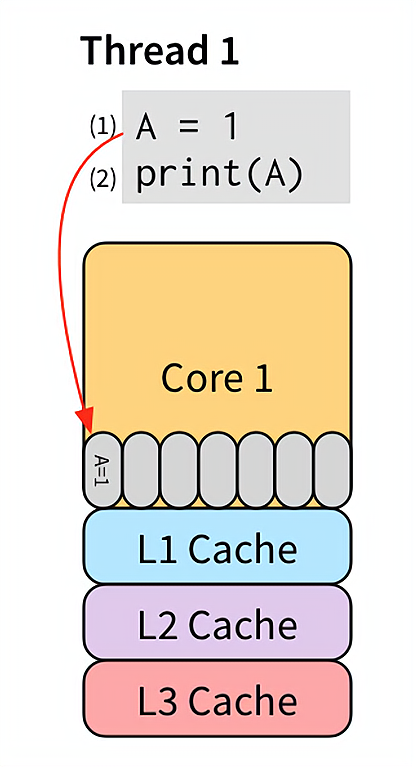
将 (1) 存入 store buffer 后,(2) 开始执行。注意,由于是同一个线程,所以语句的执行顺序还是要保持的。(2) 直接从 store buffer 里读出了 A = 1,不必从 L3 Cache 或者内存读取,简直完美!
有了 store buffer 的概念,我们再来研究前面的那个例子:
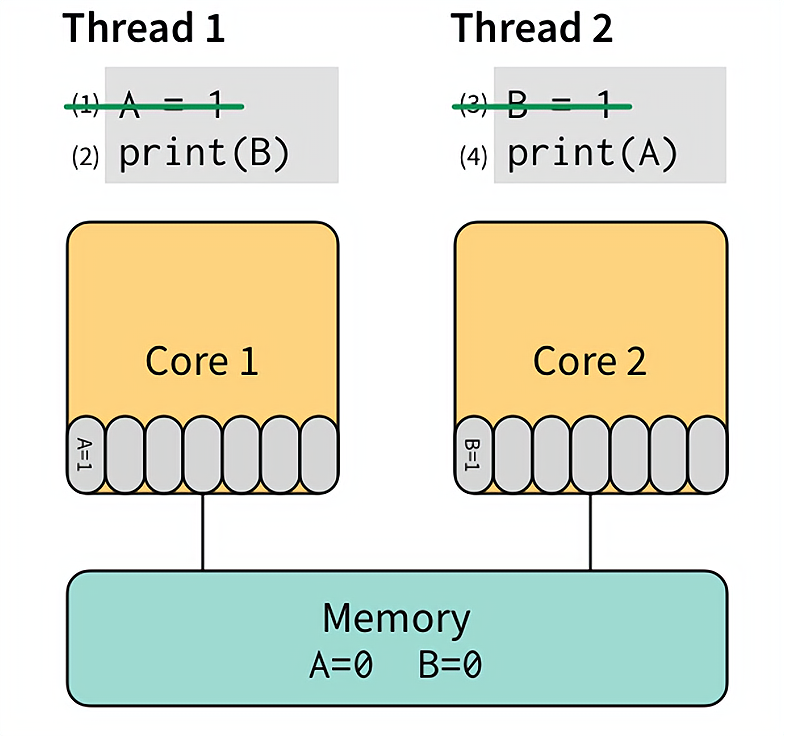
如果先执行 (1) 和 (3),将他们直接写入 store buffer,接着执行 (2) 和 (4)。“奇迹”要发生了:(2) 看了下 store buffer,并没有发现有 B 的值,于是从 Memory 读出了 0,(4) 同样从 Memory 读出了 0。最后,打印出了 00。
因此,对于多线程的程序,所有的 CPU 都会提供“锁”支持,称之为 barrier 或者 fence,即 内存屏障。barrier 指令要求所有对内存的操作都必须要“扩散”到 memory 之后才能继续执行其他对 memory 的操作。
但 barrier 指令要耗费几百个 CPU 周期,而且容易出错。因此,我们可以用高级点的 atomic compare-and-swap,或者直接用更高级的锁,通常是标准库提供。
正是 CPU 提供的 barrier 指令,我们才能实现应用层的各种同步原语,如 atomic,而 atomic 又是各种更上层的 lock 的基础。
# 2.3 Happens Before 的定义
为了说明读和写的必要条件,我们定义了 Happens Before(事件发生顺序),它表示 Go 程序中内存操作执行的偏序关系。若事件 发生在 之前,那么我们就说 发生在 之后。换言之,若 既未发生在 之前,也未发生在 之后,那么我们就说 和 是并发的。
若以下条件均成立,则对变量 v 的读操作 被允许 看到对 v 的写操作 :
- 不先行发生于 ;
- 在 后 前没有对 v 的其他写操作。
为了保证对变量 v 的读操作 看到对 v 的写操作 ,要确保 是 被允许看到的 唯一写操作。即当下面条件满足时, 被保证 看到 :
- 先行发生于 ;
- 其他对共享变量 v 的写操作要么在 前,要么在 后。
这一对条件比前面的条件更严格,需要没有其他写操作与 或 并发发生。
在单个 goroutine 当中这两个条件是等价的,因为单个 goroutine 中不存在并发,在多个 goroutine 中就必须使用同步语义来确保顺序,这样才能到保证能够监测到预期的写入。
# 2.4 机器字
对大于单个机器字的值进行读取和写入,其表现如同以不确定的顺序对多个机器字大小的值进行操作。
要理解这个我们首先要理解什么是机器字。我们现在常见的有 32 位系统和 64 位的系统,CPU 在执行一条指令的时候对于单个机器字长的的数据的写入可以保证是原子的。
对于 32 位的就是 4 个字节,对于 64 位的就是 8 个字节,对于在 32 位情况下去写入一个 8 字节的数据时就需要执行两次写入操作,这两次操作之间就没有原子性,那就可能出现先写入后半部分的数据再写入前半部分,或者是写入了一半数据然后写入失败的情况。也就是说虽然有时候我们看着仅仅只做了一次写入但是还是会有并发问题,因为它本身不是原子的。